ProxmoxにMS SQL Serverをインストール [SQLポケリ]
![DSC_1228[1].jpg](https://asai-atsushi.c.blog.ss-blog.jp/_images/blog/_f55/asai-atsushi/DSC_12285B15D.jpg)
RDBMSにおけるJSONの扱いについて調査中である。
MS SQL ServerにおいてもJSONデータを扱うことができる。これは調査せねばと思ってはいたものの、WindowsマシンにSQL Server入れないといけないしなぁ...
メインマシンの環境が変になるのもいやだから、ミニPCでも買ってSQL Server入れてみるか?
いや、MacBookにWindowsを入れたのでそこにインストールしたらいいじゃん。
と思いインストールしている最中にネット検索すると、SQL Server 2022はLinuxでも動くらしい。ということを発見。
SQL Server on Linux のインストール ガイド
なになに、RedHatとUbuntu、Dockerでも動くの?
そうか、クラウドで動かしてるもんね。今やSQL ServerもLinuxで動くんだなぁ。しみじみ。
じゃあ、うちのProxmoxでもMS SQL Serverを動かすことができるのでは?
さっそくやってみた。
まずは、UbuntuのVM作るか。さすがに、MSSQL用のLXCテンプレートは用意されていないのでVM作って、Dockerイメージを持ってきてDocker上で動かすのが簡単そう。
元ネタはここ
クイック スタート:Docker を使用して SQL Server Linux コンテナー イメージを実行する
ubuntu-22.04.1-live-server-amd64のISOイメージがあったのでこれを使ってubuntuをVMにインストール。
dockerが入ってないみたいなのでaptでインストール。
なんか入った。
.png)
マイクロソフトのリポジトリからdockerイメージをpullしろと...
入ったぽい。
後はSAのパスワードを指定してdockerイメージを走らせればOKなようだが...
sudoでパスワードを求められるが起動した模様。後でsudoersを編集してパスワードなしでも起動できるように設定しておこう。
接続確認はsqlcmdで行うらしい。このコマンド、dockerコンテナ内で実行するみたい。
えーめんどくさい。
VSCodeのMSSQL拡張を使うか。これもまためんどうだなぁブツブツ。
ファイアウォールのポート1433開けなくては。なんかSSL証明書がどうのっていわれたぞ。これはどうすれば...
うちのProxmoxは外に出ているわけではないので、ちゃんとしたSSL証明書じゃないのよ。V6プラスなのでLetsEncryptでの取得がめんどくさいのでやってない。
settings.jsonでencryptをfalseにしたら乗り切れた。
やれやれ。
.png)
サイト内を検索
JSONオブジェクトと第一正規形【その3 json_transform】 [SQLポケリ]
前回に続きRDBMSにおけるJSON型の話である。
前回では、JSONデータのうちJSON配列をRDBMSのテーブルのように変換する方法について解説した。
今回はOracleにおいてJSONデータを変更できるjson_transform関数を紹介する。
json_transform
OracleにおいてJSONデータを変更できる関数。
なんとselectで値を変更できる。マジか。
どういう変更ができるかというと
| REMOVE | データを削除 |
| KEEP | 指定されたもの以外を削除 |
| RENAME | フィールド名を変更 |
| SET | 値の変更もしくは追加 |
| REPLACE | 値の変更 |
| INSERT | データの追加 |
| APPEND | 配列の末尾にデータを追加 |
といった感じである。
まぁ普通に配列の要素やフィールドの追加、削除、更新ができるのであろう。
編集対象はJSONパス式で指定するみたい。
パスで指定された要素やフィールドが存在しない場合の挙動は各サブコマンドで異なる。エラーにしたり無視したりするオプションがある。
まぁ、こんだけあればなんでもできるように思える。
REMOVE
順番にやってみるか。
この前作ったJSONデータで配列要素の0番目を削除してみるか。
SQL> select json_transform(j, remove '$[0]') from jfoo;
JSON_TRANSFORM(J,REMOVE'$[0]')
--------------------------------------------------------------------------------
[{"name":"suzuki","age":32},{"name":"honda","age":45}]
[{"name":"syouhei","age":25}]
[]
おお、なんかできたぞ。
json_transformの第一引数にはJSONデータを渡す。
第二引数にはサブコマンドとそれに続けてJSONパス式を書く。
サブコマンドによるが、パス式の後にJSONデータが必要になる場合もあり。REMOVE、KEEPの場合は必要ない。
json_transformは処理後のJSONデータを戻してくる。
結果をみると確かに実行前にあったはずの要素がひとつ消えている。
ふと「しまった、追加してから消せばよかったかも」と後悔するのだが、Oracleならデフォルトでトランザクションかかっているから、ROLLBACKすればいいじゃん。でも、SELECTしかしてないけど... ROLLBACK効くのか?
やってみた。
SQL> rollback;
ロールバックが完了しました。
SQL> select j from jfoo;
J
--------------------------------------------------------------------------------
[{"name":"asai","age":58}, {"name":"suzuki","age":32}, {"name":"honda","age":45]]
[{"name":"ichiro","age":52}, {"name":"syouhei","age":25}]
[{"name":"honda","age":45}]
できた!
ムムム、これは気を付けないと「ヤバいやつ」かも知れない。
SELECT命令ではデータを更新しないので「ロックは発生しない」と思っているとハマる可能性があるのね。まぁ、今までもSELECT FOR UPDATEみたいなことをすればロックがかかるのでjson_transformを使うとFOR UPDATEが付くよっていう風に覚えておく。
KEEP
データが戻ったので今度はKEEPをやってみるか。REMOVEが指定されたデータを削除するのに対して、KEEPは指定されたものは残して(KEEPして)他を削除する。
SQL> select json_transform(j, keep '$[0]') from jfoo;
JSON_TRANSFORM(J,KEEP'$[0]')
--------------------------------------------------------------------------------
[{"name":"asai","age":58}]
[{"name":"ichiro","age":52}]
[{"name":"honda","age":45}]
なるほど。
わかったのでROLLBACKして戻しておく。
APPEND
削除したら今度は追加かな。簡単だと思われる配列の末尾に要素を追加するAPPENDをやってみる。JavaScriptならpushかな。
select json_transform(j, append '$' = '{"name":"kawasaki","age":10}' format json) from jfoo;
JSON_TRANSFORM(J,APPEND'$'='{"NAME":"KAWASAKI","AGE":10}'FORMATJSON)
--------------------------------------------------------------------------------
[{"name":"asai","age":58},{"name":"suzuki","age":32},{"name":"honda","age":45},{"name":"kawasaki","age":10}]
[{"name":"ichiro","age":52},{"name":"syouhei","age":25},{"name":"kawasaki","age":10}]
[{"name":"honda","age":45},{"name":"kawasaki","age":10}]
うーんできちゃった。format jsonを付けないとJSONデータとみなされないので注意。
これもROLLBACKして戻す。
INSERT
配列の先頭に要素を追加する場合はINSERTを使う。JavaScriptならunshift?
SQL> select json_transform(j, insert '$' = '{"name":"kawasaki","age":10}' format json) from jfoo;
行1でエラーが発生しました。:
ORA-40810: ルート値の更新は許可されていません JZN-00409:
JSON_TRANSFORMではルート値を更新できません
なんですと?ルート値は変更できないとのこと。ルート値というのは「どうも$のこと」らしいぞ。
どうすれば...末尾に追加する際のAPPENDではどこに追加するのかが決定しているので$の指定だけでよかったのだが、INSERTではどの位置に追加するのかを指定しないといけないらしい。位置は要素のインデックスで指定する。
SQL> select json_transform(j, insert '$[0]' = '{"name":"kawasaki","age":10}' format json) from jfoo;
JSON_TRANSFORM(J,INSERT'$[0]'='{"NAME":"KAWASAKI","AGE":10}'FORMATJSON)
--------------------------------------------------------------------------------
[{"name":"kawasaki","age":10},{"name":"asai","age":58},{"name":"suzuki","age":32},{"name":"honda","age":45}]
[{"name":"kawasaki","age":10},{"name":"ichiro","age":52},{"name":"syouhei","age":25}]
[{"name":"kawasaki","age":10},{"name":"honda","age":45}]
今度はできた。
JavaScriptのunshiftでは必ず先頭に追加される。json_transformでのINSERTは要素位置を指定できるので、spliceの方に近いのかも。
ちなみに、insert $[last+1] のようにパスを指定するとAPPENDと同じになる。
SET
削除、追加ときたので次は更新だな。
SETで値を変更できる。このフィールドの値だけ変えたいんだよねぇっていうケースはけっこうあると思う。
SQL> select json_transform(j, set '$[0]' = '{"name":"kawasaki","age":10}' format json) from jfoo;
JSON_TRANSFORM(J,SET'$[0]'='{"NAME":"KAWASAKI","AGE":10}'FORMATJSON)
--------------------------------------------------------------------------------
[{"name":"kawasaki","age":10},{"name":"suzuki","age":32},{"name":"honda","age":4
5}]
[{"name":"kawasaki","age":10},{"name":"syouhei","age":25}]
[{"name":"kawasaki","age":10}]
JSONパスでフィールド名まで指定することもできる。
SQL> select json_transform(j, set '$[0].name' = '"kawasaki"' format json) from jfoo;
JSON_TRANSFORM(J,SET'$[0].NAME'='"KAWASAKI"'FORMATJSON)
--------------------------------------------------------------------------------
[{"name":"kawasaki","age":58},{"name":"suzuki","age":32},{"name":"honda","age":4
5}]
[{"name":"kawasaki","age":52},{"name":"syouhei","age":25}]
[{"name":"kawasaki","age":45}]
要素0のnameフィールドだけ変更してみた。
setで更新するときはSQLのUPDATE命令使いたくなるなぁ...と思ったらOracleのマニュアルにもUPDATEでやる例が載っているじゃないの。
SQL> update jfoo set j = json_transform(j, set '$[0].name' = '"kawasaki"' format json); 4行が更新されました。
RETURNINGしていないから結果が見えなくて、ちゃんとできているのか不安だが、SELECTで確認したらちゃんと更新されてた。
ということは、今までSELECTでやってみてたけど、UPDATEでもできるのね。
JSONデータを更新した後で結果を見たい場合 -> select json_transform()
別に結果は見なくてよい場合 -> update xxx set j = json_transform()
と使い分けるのが良いかも。
REPLACE
REPLACEでも値を更新することができる。SETとの違いはJSONパスと一致するJSONデータが存在しない場合の挙動。SETではパスが見つからない場合はその位置に新規にフィールドなり配列要素なりを作って更新する。REPLACEでは対象が見つからない場合、単に更新されない。
じゃあやってみるか。
addressという名前のフィールドが存在してないのでaddressフィールドに値をREPLACEで更新してみよう。
SQL> select json_transform(j, replace '$[0].address' = '"埼玉県"' format json) from jfoo;
JSON_TRANSFORM(J,REPLACE'$[0].ADDRESS'='"埼玉県"'FORMATJSON)
--------------------------------------------------------------------------------
[{"name":"asai","age":58},{"name":"suzuki","age":32},{"name":"honda","age":45}]
[{"name":"ichiro","age":52},{"name":"syouhei","age":25}]
[{"name":"honda","age":45}]
まぁ、当たり前の挙動な感じ。
SQLのUPDATE命令で更新の対象行が存在しない場合でもエラーにはならないことと似ている。
REPLACEをSETに変更してやってみよう。
SQL> select json_transform(j, set '$[0].address' = '"埼玉県"' format json) from jfoo;
JSON_TRANSFORM(J,SET'$[0].ADDRESS'='"埼玉県"'FORMATJSON)
--------------------------------------------------------------------------------
[{"name":"asai","age":58,"address":"埼玉県"},{"name":"suzuki","age":32},{"name":"honda","age":45}]
[{"name":"ichiro","age":52,"address":"埼玉県"},{"name":"syouhei","age":25}]
[{"name":"honda","age":45,"address":"埼玉県"}]
ふーん。addressフィールドが追加されてる!
フィールドでやってみたが、配列要素でも自動で追加されるみたい。
なのだが、なんか恐ろしいことが書いてある。
指定されたJSONパスが配列の大きさを超えるような場合、配列の大きさが自動調整される
マジか。
調整された配列の間にできた隙間はnullで埋められる
ホントに?
ヤバいな。配列の添え字をミスると大変なことになりそう。
例えば...
select json_transform(j, set '$[10000]' = '{"address":"埼玉県"}' format json) from jfoo;
こんなことしたら10000個のnullが隙間に埋められるのか?
やってみるか。
SQL> select json_transform(j, set '$[0].address' = '"埼玉県"' format json) from jfoo; 行1でエラーが発生しました。: ORA-40478: 出力値が大きすぎます(最大: 4000) JZN-00018: シリアライザへの入力が大きすぎます
ああ、なるほど。CLOB型でもない限り巨大なJSONデータは持てないわけね。
そこはひとまず安心するか。
他RDBMSでのJSONデータ変更
今回はOracleでのjson_transformについて調べてみた。json_transform()を使うとSELECT命令内であってもトランザクションが発生することがわかった。
JSONパスにしてもJavaScript寄りな考えになっているなぁと感じた。
最近はPostgresを扱うことが多いのだが、ポスグレにjson_transform()は存在しない。
MySQLはOracleに引き取られたのでjson_transformもあるのかな?と思ったが、json_insert()やjson_remove()、json_set()、json_replace()といった関数が存在している。
MS SQL Serverでは、json_modify()関数がある。
よくよく調べたらポスグレにもjsonb_set()とかjsonb_insert()があるじゃない。
ちょっとなんか困るぅ。
どうしてこうもバラバラなのよ。
SQLやJSONとは無関係なのだが、新しく本が出るのでその宣伝をしておく。いわゆる案件である。

3ステップでしっかり学ぶ Visual Basic入門 改訂第3版
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2024/03/04
- メディア: 単行本(ソフトカバー)
なんのことはない、Visual Studioが新しくなったので改訂版が出ますということだけでした。
みなさん宜しくお願い致します。
サイト内を検索
JSONオブジェクトと第一正規形【その2】 [SQLポケリ]
前回に続きRDBMSにおけるJSON型の話である。
前回では、JSON型の列に格納されているJSONデータから「一部を取り出す方法」についてみてきた。演算子->>を使う方法、JSONパスといくつか方法がある。
今回は、JSONデータのうちJSON配列をRDBMSのテーブルのように変換する方法について解説したいと思う。
JSON配列のテーブル化
JSON配列をテーブルのように扱うことができれば、SQL命令でJSONデータを操作できるので便利だと容易に想像できる。
例えば、JSON配列に格納されているJSONオブジェクトのうち「idフィールドが1であるオブジェクトを検索する」といった操作を、使い慣れているSELECT命令で書けると便利でしょ?
これを実現するためにはJSONデータをテーブルに置き換えるという処理が必要なのだが、データベース毎に事情があるようなので、個別に見ていくことにしよう。
まずは、PostgreSQLである。ポスグレではjsonb_to_recordsetでJSONデータをテーブルのように変換することができる。
select * from jsonb_to_recordset('[{"name": "asai","age": null},{"name": "taro","age": 30},{"name": null,"age": 40}]'::jsonb)
as json_data("name" text, "age" integer)
name age
------- ------
asai
taro 30
40
JSON配列の要素がレコードとなり、配列要素であるJSONオブジェクトのフィールドが列になって結果として得られる。
jsonb_to_recordsetでは別名指定のASで列名と型を指定する必要がある。
得られる結果はテーブルではなくレコードセットであるため参照のみが可能。残念ながら更新系の命令では使用できない。SELECT命令でのみ使用できるが、FROM句で使用するのが定石。
別名で付けた列名はSELECT句、WHERE句で使用することができる。
select name from jsonb_to_recordset('[{"name": "asai","age": null},{"name": "taro","age": 30},{"name": null,"age": 40}]'::jsonb)
as json_data("name" text, "age" integer)
where name is not null and age is not null
name
-------
taro
次にOracleである。オラクルさんではjson_tableという関数でJSONデータをテーブル化できる。
select * from json_table('[{"name": "asai","age": null},{"name": "taro","age": 30},{"name": null,"age": 40}]',
'$[*]' columns(name varchar2(8) path '$[*].name', age number path '$[*].age'))
as json_data
name age
------- ------
asai
taro 30
40
ポスグレのjsonb_to_recordsetと同じ感じだけど、JSONパスで列を指定しないとうまくいかない。ネストが深くなると大変。
別名で付けた列名はSELECT句、WHERE句で使用することができる。
select name from json_table('[{"name": "asai","age": null},{"name": "taro","age": 30},{"name": null,"age": 40}]',
'$[*]' columns(name varchar2(8) path '$[*].name', age number path '$[*].age'))
as json_data where name is not null and age is not null
name
-------
taro
さて、JSONデータをポスグレのjsonb_to_recordset()や、オラクルのjson_table()でテーブルのように変換してSELECT命令で使えることを見てきたわけではあるが、実際のJSONデータはテーブルのJSON列に格納されていることが多いであろう。
まぁちょっとサンプルのデータを作ってみる。ますはポスグレ。
create table jfoo (
a integer not null,
j jsonb
);
insert into jfoo values(1,'[
{"name":"asai","age":58},
{"name":"suzuki","age":32},
{"name":"honda","age":45}]');
insert into jfoo values(2,'[
{"name":"ichiro","age":52},
{"name":"syouhei","age":25}]');
insert into jfoo values(3,'[
{"name":"honda","age":45}]');
とりあえずできたので確認してみよう。
postgres=# select * from jfoo;
a | j
---+--------------------------------------------------------------------------------------------
1 | [{"age": 58, "name": "asai"}, {"age": 32, "name": "suzuki"}, {"age": 45, "name": "honda"}]
2 | [{"age": 52, "name": "ichiro"}, {"age": 25, "name": "syouhei"}]
3 | [{"age": 45, "name": "honda"}]
ふむふむ、なかなかいい感じではないかな。
一応説明するとa列はレコード番号。連番で1、2、3と入れてみた。
j列がJSONデータで内容はnameとageフィールドを持つオブジェクトの配列が格納されている。
JSON型が無かった頃のRDBMSだとnameとage列を持つ別テーブルにして結合して使うような感じかな。
JSON型を導入することで、テーブル分割しなくて済むし、結合もしなくて良いので楽チンなんだけどJSON配列の要素を別々に見たい場合にはやはり結合する必要がある。
postgres=# select a, name, age from jfoo inner join jsonb_to_recordset(j) as (name varchar(10), age integer) on true; a | name | age ---+---------+----- 1 | asai | 58 1 | suzuki | 32 1 | honda | 45 2 | ichiro | 52 2 | syouhei | 25 3 | honda | 45
自己結合なのでon以下の結合条件が「trueだけ」でなんか気持ち悪いけど、まぁこんな感じになる。inner joinじゃなくてcross joinにすればonの条件式は書かなくてOK。
j列がnullの場合もあり、そのレコードも含めるのなら、left joinを使えばよい。
postgres=# select a, name, age from jfoo left join jsonb_to_recordset(j) as (name varchar(10), age integer) on true; a | name | age ---+---------+----- 1 | asai | 58 1 | suzuki | 32 1 | honda | 45 2 | ichiro | 52 2 | syouhei | 25 3 | honda | 45 4 | |
テーブルがひとつだけなのに結合しなくちゃいけなくて、しかも自己結合だからなんかよくわからん状態。これに他のテーブルとさらに結合するとなると、またちょっとややこしくなる。
試しにやってみよう。テーブルjbarを作って結合させてみる。
create table jbar ( a integer not null, b varchar(32) not null ); insert into jbar values(1,'no name'); insert into jbar values(2,'asai'); insert into jbar values(3,'suzuki'); insert into jbar values(4,'honda');
b列にnameフィールドの内容を入れてみた。これで結合させたい。
postgres=# select jfoo.a, j.name, j.age, jbar.a
from jfoo
cross join jsonb_to_recordset(j)
as j(name varchar(10), age integer)
left join jbar
on j.name = jbar.b;
a | name | age | a
---+---------+-----+---
2 | syouhei | 25 |
1 | suzuki | 32 | 3
1 | asai | 58 | 2
3 | honda | 45 | 4
1 | honda | 45 | 4
2 | ichiro | 52 |
なんかうまくいったぽいけど...ややこしい。
NESTED
Oracleでも同じようにできる。jsonb_to_recordset()ではなくjson_table()を使えば良い。
SQL> select jfoo.a, j.name, j.age, jbar.a
from jfoo
cross join json_table(j, '$[*]'
columns (name varchar2(10), age number)) as j
left join jbar
on j.name = jbar.b;
A NAME AGE A
---------- ---------- ---------- ----------
1 asai 58 2
1 suzuki 32 3
1 honda 45 4
2 ichiro 52
2 syouhei 25
3 honda 45 4
json_tableの場合は第二引数にJSONパス式を書く必要がある。jsonb_to_recordsetでは別名で列定義していたが、json_tableでは専用のcolumnsで列定義する。細かい違いだが注意しないとハマりそう。
Oracleにはうれしいことに、シンタックスシュガーが用意されている。それは何かというと「NESTED」である。
NESTEDの本来の目的は、JSONデータの中にいくつも配列がネストして存在している場合でも対応できるように考えられた「もの」らしいが、JOINをすっきり書けるので「おすすめ」である。
SQL> select jfoo.a, name, age, jbar.a
from jfoo
nested j[*] columns (name varchar2(10), age number)
left join jbar
on name = jbar.b;
A NAME AGE A
---------- ---------- ---------- ----------
1 asai 58 2
1 suzuki 32 3
1 honda 45 4
2 ichiro 52
2 syouhei 25
3 honda 45 4
普通の結合ではないみたいなので、ASで別名を付けることができなかった。別名を付けたい場合はjson_tableを使えということなのかな。
MS SQL ServerのOPENJSON
ついでにSQL ServerでのJSON配列のテーブル化について調査したので載せておく。
SQL ServerではOPENJSONでJSONデータをテーブル化することができる。JSONが後に付いているのでなんだか仲間外れな気がするがそういうものなのでしょうがないとする。
select jfoo.a, oj.name, oj.age from jfoo cross apply openjson(j) with(name nvarchar(32), age integer) as oj; a | name | age ---+---------+----- 1 | asai | 58 1 | suzuki | 32 1 | honda | 45 2 | ichiro | 52 2 | syouhei | 25 3 | honda | 45 4 | |
使い方はjson_tableやjson_to_recordsetと同じようにする。列定義はwithで行う。
SQL Serverではcross applyを使って結合できる。
UPDATEできるか
JSON配列をテーブル化したものに対してUPDATEやINSERTが使えたら便利なんじゃない?と思ったりする。例えば以下のような感じ
update jsonb_to_recordset('[{"name": "asai","age": null},{"name": "taro","age": 30},{"name": null,"age": 40}]'::jsonb)
as json_data("name" text, "age" integer)
set name = name || '様'
where name is not null
残念ながら、このクエリはエラーになり実行できない。
jsonb_to_recordsetが戻すデータはあくまでもレコードセットなのでテーブルとはちょっと違うものになっている。
クエリの実行結果をクライアント側に持ってきたデータである「ミドルウェアでのレコードセット」と似ているかも知れない。レコードセットに対して仮に書き換えが可能だとしてもそれはクライアント側での話で、サーバに反映させるには別の手段が必要。
JSONデータの一部を書き換えたり削除するには一度JavaScript環境に持ってきてオブジェクトを編集してJSONデータを書き戻す、というのが手っ取り早い。SQLだけでやるのはちょっとしんどいかも。
OracleやMySQLにはjson_transformという関数が用意されていて、JSONデータを操作できるようなのだが、これについては勉強中なので少々お待ちを。次回は解説したいけど、どうかな?
SQLやJSONとは無関係なのだが、新しく本が出るのでその宣伝をしておく。いわゆる案件である。
3ステップでしっかり学ぶ Visual Basic入門 改訂第3版
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2024/03/04
- メディア: 単行本(ソフトカバー)
なんのことはない、Visual Studioが新しくなったので改訂版が出ますということだけでした。
みなさん宜しくお願い致します。
サイト内を検索
JSONオブジェクトと第一正規形 [SQLポケリ]
本日は、RDBMSにおけるJSON型のお話である。
RDBMSって何?JSONって何?な人はまずはそれらを勉強してからでないと「まるで話がわからない」と思うので注意されたし。
多くの場合JSON型の列に入れる値はJSONオブジェクトか配列であろう。文字列や数値を格納するメリットがあまり思いつかない。JSONオブジェクトや配列をセル(フィールド)に格納した場合、第一正規形にならない。何を言っているのかさっぱりという方に向け少し説明すると、RDBMSでは「ひとつのセルにはひとつのデータを格納する」といった定石(セオリー)みたいなものがある。この定石に従っている表データが「第一正規形」と呼ばれる。
閑話休題、ここで宣伝である。正規化についてはSQLポケリには書いてない。データベース設計の話になるからね。「SQLはじめの一歩」には載っているので興味のある方はこちらを参照して欲しい。
![[データベースの気持ちがわかる]SQLはじめの一歩 (WEB+DB PRESS plus)](https://m.media-amazon.com/images/I/510-kU4HwjL._SL160_.jpg "[データベースの気持ちがわかる]SQLはじめの一歩 (WEB+DB PRESS plus)")
[データベースの気持ちがわかる]SQLはじめの一歩 (WEB+DB PRESS plus)
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2015/03/03
- メディア: 単行本(ソフトカバー)
JSONオブジェクトは複数のデータをまとめることができるので、セルの中に複数のデータを記録することができ、RDBMSの伝統的な掟である「第一正規形」に違反してしまうのである。JSON型は掟破りの必殺技なのである。
まぁ、第一正規形などの正規化が考えられたのは、もう何十年も前の話。かつて最強と思われた定石は今や古臭いものとなってしまったのかも知れない。
ちょっと話が逸れ始めてしまったではないか。元に戻そう。JSON型の列にはその値としてJSONオブジェクト・配列を記録することが多いのだが、そうすることで第一正規形ではなくなる。
元々SQLはレコードのフィールド(テーブルのセル)にはひとつの値しか格納しないことが前提となっている。そう、JSON型により掟破りなデータが入り込むのである。昔のSQLにはJSON型を扱うようなしくみがないことはもちろんのこと、開発スピードが速く標準化が間に合わず各RDBMSで独自仕様の拡張がなされ「方言が多い」状態になっている。
と嘆いてみてもしょうがない。各RDBMSごとにどうなっているのかを見ていくことにしよう。
PostgreSQLにおけるJSON
PostgreSQLでは割と前からJSON型に対応している気がする。普通にJSON型があるし、JSONBといったバイナリ形式のJSON型もある。JSONはJavaScript文法の一部なので、テキストデータといっても良い。JSON型が使えないRDBMSでも通常の文字列型にJSONデータを保存することが可能なのでテキストデータであることは明白であるのだが、わざわざJSON型を使う理由としては...
JSON型にすると文法チェックが入るのでデータの整合性を高めることができる。これがJSON型を使うことのメリットである。さらに、バイナリのJSON型にすると内部で扱いやすいように構造を変えて保存されるらしい。詳しい事柄はよくわからないが、内部処理が省けるのでJSONよりJSONBの方が高速、ということみたい。JSONBにはインデックスを作成することができるので、検索が速くなるらしいが、どの程度なのかはよくわからない。
さて、そんなJSON型には当然ながらJSONデータを格納することができる。前にも言及した通りRDBMSにおいて扱われるJSONデータはJSONオブジェクトかJSON配列が多いであろう。。
JSONオブジェクトとJSON配列は構造としてはどちらも同じようなもの。添え字が整数であるのが配列で、添え字が文字列なのがオブジェクトである。
| JSON配列 | JSONオブジェクト | JSONオブジェクト(フィールド名表記) |
|---|---|---|
| 添え字が整数 | 添え字が文字列 | フィールド名 |
| var[0] = "zero" | var["zero"] = 0 | var.zero = 0 |
| var[1] = "one" | var["one"] = 1 | var.one = 1 |
PostgreSQLにおけるJSONオブジェクトの各フィールドへのアクセスは、->を使う。
JSON型の列名に->を付け、その後に整数値か文字列を付け足すことでJSONオブジェクトの子要素を参照することができる。
select jobj, jobj->0 e0 from testjson
jobj e0
--------------------- -------------
["zero","one"] "zero"
{"zero": 0,"one": 1}
jobj->0とすれば、JSON型の列jobjから配列要素の先頭(0番目)だけを取得することができる。jobjに配列ではなくJSONオブジェクトが保存されているときっとうまくいかない。NULLが戻される。
select jobj, jobj->'one' one from testjson
jobj one
--------------------- -------------
["zero","one"]
{"zero": 0,"one": 1} 1
jobj->'one'とすれば、JSON型の列jobjからoneフィールドだけを取得することができる。jobjに配列が保存されているときっとうまくいかない。NULLが戻される。
JSONでの文字列は"で囲むが、SQLでは'で囲む。
->ではJSON型から抽出してJSON型で結果を戻す。これに対して、>をふたつにして->>とすることでtext型で結果を戻すようにすることができる。
select jobj, jobj->>0 e0 from testjson
jobj e0
--------------------- -------------
["zero","one"] zero
{"zero": 0,"one": 1}
"zero"とzeroの違いがある。
* MySQLにおいても-> ->>を使ってフィールド/要素アクセス可能だが、$.フィールド名のようにする必要あり。微妙に異なる。
* Oracleには->は存在しない。.でフィールド指定する。型を指定する場合は.string()や.number()を付ける。
* Oracle、MySQLではJSON_VALUE関数でJSONデータからパスを使用して値を抽出することができる。
JSON_TYPEOF
JSON型にはJSONデータを格納することができるが、JSONデータには以下の種類がある。
| データ型 | JSON_TYPEOFの戻り値 |
|---|---|
| オブジェクト | object |
| 配列 | array |
| 文字列 | string |
| 数値 | number |
| 論理値 | boolean |
フィールドにどういった種類のJSONデータが格納されているのかについてはJSON_TYPEOF関数を使って調べることができる。
select jobj, json_typeof(jobj) json_type from testjson
jobj json_typeof
--------------------- -------------
["zero","one"] array
{"zero": 0,"one": 1} object
* MySQLではJSON_TYPEを使用する。
オブジェクトのネスト
JSONではデータをネストさせることができる。配列の各要素がオブジェクトであったり、その逆でオブジェクトのフィールドが配列となっていたりしてもOKなのである。
配列の各要素がオブジェクトの例
[{"name": "asai","age": null},{"name": "taro","age": 30}]
オブジェクトのフィールドが配列の例
{"one_tow_three": [1, 2, 3]}
オブジェクトのフィールドがオブジェクトの例
{"one": {"name": "asai","age": null}, "two": {"name": "taro","age": 30}}
いろいろな組み合わせが無限に考えられるが、多くても4階層くらいまでかな。ツリー構造になっていると、もっとネストが深くなるかも知れないけど。
ネストしているJSONオブジェクトにアクセスしたい場合は、->を連続して使うことも可能だが、パスで指定することも可能。パスの場合は#>を使用する。
oneフィールドの下にあるnameフィールドを->の連続で抽出
select '{"one": {"name": "asai","age": null}, "two": {"name": "taro","age": 30}}'::json->'one'->'name' one_name
one_name
---------
"asai"
oneフィールドの下にあるnameフィールドを#>とパスで抽出
select '{"one": {"name": "asai","age": null}, "two": {"name": "taro","age": 30}}'::json
#>'{one, name}' one_name
one_name
---------
"asai"
#>はjson_extract_path関数に、#>>はjson_extract_path_text関数とそれぞれ置き換え可能。
SQL/JSONパス式
PostgreSQL12になってJSON関係の機能が追加されている。JSONパス式もそのひとつである。パス式はSQL/JSON標準で規定されている規格となっている。#>のところで解説したパスとは別物になっているので注意されたし。
JSONパス式は$から始める。$がルートを意味する。
.に続けてフィールド名を指定することができる。
配列要素は[0]のように指定できるが、メタ文字である*を使用することも可能。[*]とすれば全要素が対象になる。
これだけ押さえておけば大体は把握できたと思っても良い?だろう。
簡単な例からやってみるか。
oneフィールドの下にあるnameフィールドをJSONパスで抽出
select jsonb_path_query('{"one": {"name": "asai","age": null}, "two": {"name": "taro","age": 30}}'::jsonb,
'$.one.name'::jsonpath) one_name
one_name
---------
"asai"
jsonb_path_queryはJSONB型のデータからJSONパスに合致するJSONデータを戻す関数。
JSONパスは「$.one.name」となっている。これで、oneフィールドの下にあるnameフィールドが抽出できる。
*Oracle23cではjson_query関数を使用する。
select json_query('{"one": {"name": "asai","age": null}, "two": {"name": "taro","age": 30}}',
'$.one.name') one_name
one_name
---------
"asai"
続けて、配列の例を見てみよう。
配列の各要素からnameフィールドだけを抽出
select jsonb_path_query('[{"name": "asai","age": null},{"name": "taro","age": 30}]'::jsonb,
'$[*].name') name_value
name_value
----------
"asai"
"taro"
JSONパスは「$[*].name」となっている。これで、全要素のnameフィールドが抽出できる。*が任意の添え字=全要素を意味している。配列にはふたつの要素があるので結果は2行になる。
このようにjsonb_path_queryでは複数行が戻される場合があることに注意。jsonb_path_query_arrayを使うことで、結果を配列に集約させることができる。
配列の各要素からnameフィールドだけを配列に集約して抽出
select jsonb_path_query_array('[{"name": "asai","age": null},{"name": "taro","age": 30}]'::jsonb,
'$[*].name') name_value
name_value
----------------
["asai", "taro"]
*Oracle23cではjson_query関数にwith array wrapperオプションを付けて使用する。
select json_query('[{"name": "asai","age": null},{"name": "taro","age": 30}]',
'$[*].name' with array wrapper) name_value
name_value
----------------
["asai", "taro"]
うーんやっぱり方言は残ってしまうのか。
条件式
JSONパスでは条件式を付けることができる。
配列の各要素からageフィールドだけを抽出するがnullであるものは除く
select jsonb_path_query('[{"name": "asai","age": null},{"name": "taro","age": 30}]'::jsonb,
'$[*].age ? (@ != null)') age_value
age_value
----------
30
JSONパス式に?を追加して、さらに(と)の間に条件式を書けばよい。@はパス式にマッチしたJSONオブジェクトを意味する。
*Oracle23cではjson_query関数を使用する。
select json_query('[{"name": "asai","age": null},{"name": "taro","age": 30}]',
'$[*].age ? (@ != null)') age_value
age_value
----------
30
ageがnullでない条件はそのままで、配列要素全体を取得したい場合は以下のようにもできる。
配列の各要素を抽出するがageフィールドがnullであるものは除く
select jsonb_path_query('[{"name": "asai","age": null},{"name": "taro","age": 30}]'::jsonb,
'$[*] ? (@.age != null)') obj_value
obj_value
----------
{"age": 30, "name": "taro"}
ANDやOR条件を記述することも可能だが、JavaScriptでの演算子記法となる。
配列の各要素を抽出するがageフィールドかnameフィールドがnullであるものは除く
select jsonb_path_query('[{"name": "asai","age": null},{"name": "taro","age": 30},{"name": null,"age": 40}]'::jsonb,
'$[*] ? (@.age != null && @.name != null)') obj_value
obj_value
----------
{"age": 30, "name": "taro"}
話が長くなってしまったので本日は以上。
次回は、JSON配列をテーブルのように扱う方法について解説したい。
SQLやJSONとは無関係なのだが、新しく本が出るのでその宣伝をしておく。いわゆる案件である。
3ステップでしっかり学ぶ Visual Basic入門 改訂第3版
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2024/03/04
- メディア: 単行本(ソフトカバー)
なんのことはない、Visual Studioが新しくなったので改訂版が出ますということだけでした。
みなさん宜しくお願い致します。
サイト内を検索
データベースにおける正規表現【REGEXP】 [SQLポケリ]
さて、本日はようやくデータベースにおける正規表現をみていこうと思う。
まずは、Oracle23cでやってみる。
Oracle23cはProxmoxのVMにOracle Linux 8を入れてその中にOracle23cをインストールしている。
最初に紹介するのはREGEXP_LIKEである。
これはSQL標準のLIKEによるあいまい検索を「正規表現」でやる感じの関数である。
以下の例を見て貰えればわかりやすいであろう。
regexp_likeの第一引数には元となる文字列を入れる。上記の例の場合は、fooテーブルのa列を指定している。ちなみにfooテーブルのa列には以下のようなデータが格納されている。
このデータの中から正規表現「^a.*」にマッチするものだけを検索して表示させるのがregexp_likeを使った先の例文である。
regexp_likeの第一引数には元となる文字列を入れ、続く第二引数には正規表現で示した文字列を与える。
regexp_likeの機能は、第一引数で与えられた文字列の中に第二引数の正規表現で示された文字列が存在していれば真を返し、存在しなければ偽を返す、といったものになる。
第二引数の正規表現の部分にメタ文字を含んでいなくてもかまわない。これがLIKEとちょっと違う点なのでハマりポイントかも知れない。
例えばLIKEで「文字1を含むもの」といった検索をしようとしたら、以下のようにすると思う。
これをregexp_likeでやろうとしたら、以下のようにできる。
もちろんメタ文字を含んでもOK
LIKEでは「何々を含む」といった検索を行う場合、何々の前後にメタ文字%を付け、何々の前後が任意の文字列であっても検索に引っかかるようにしないといけない。
REGEXP_LIKEではメタ文字を使うことなく、単に「何々」を指定すればOKで「何々」を含むかどうかでヒットするのである。
あいまい検索の場合、その検索のやり方にいくつかパターンがあり、前方一致、後方一致などがある。「何々を含む」といった検索は部分一致になる。
前方一致は、「何々から始まる」という検索方法で、LIKEでやるなら以下のように後ろに%を付けると前方一致になる。
1から始まるものを検索。
正規表現の場合、「1.*」としても先頭の文字が1でない場合もヒットしてしまうので、先頭を意味するメタ文字である^を使って「^1.*」としなければならない。
^を付けずに実行すると...
先頭が1でないものまでヒットする。
先頭を意味するメタ文字^を加えて「^1.*」とすればLIKE '1%'と同じになる。
後方一致は逆に「何々で終わる」ものを検索する。LIKEでは「%1」とすれば良い。REGEXP_LIKEでは終わりを意味するメタ文字$を使って「.*1$」にすればOK。
合わせ技で「aで始まりcで終わる」という検索も可能。
LIKEなら「a%c」
REGEXP_LIKEなら「^a.*c$」
とすればOK。
あいまい検索を行う際に「何々」または「うんたら」の両方を検索したいっていう場合もあるでしょう。SQL命令のOR条件を使うような場合である。
例のfooテーブルから「123」か「abc」を含むものを検索する時は次のようなSQL命令になるであろう。
LIKEのメタ文字には「または」を意味するようなものが存在しない。正規表現にはグループ化という概念があり、グループのうち何れかとマッチすればOKといった検索が可能。そのため1回のREGEXP_LIKE呼び出しで上記の「123」か「abc」を含むものを検索するクエリを記述できる。
ほらね。できたでしょ。
グループは(で始まり、)で終わる。グループの中はマッチさせたい文字列を列挙するが区切りを|で表記する。3つ以上でもかまわない。
グループ内の文字列にメタ文字を含んでいても良い。
123かa.*cにマッチするものを検索。
このグループ化の機能は「大した機能じゃない」と思われるかも知れないが、置換や抽出とかやり出すと重宝する。置換についてはREGEXP_REPLACE関数で解説しようと思う。
REGEXP_LIKEは、Oracleの他、DB2、MySQLでも使用できる。PostgreSQLでは~演算子で正規表現によるパターンマッチングが可能。
次に紹介する正規表現関数は、REGEXP_COUNTである。正規表現関数は頭がREGEXPとなっている。
REGEXP_COUNTは元の文字列内に正規表現とマッチする部分文字列が、いくつあるのかを数えて戻す関数。REGEXP_LIKEがマッチする/しないを真偽で返すことに対して、REGEXP_COUNTはマッチしないのであれば0、マッチするのであればその回数を戻すため、1以上の数値となる。
WHERE条件で使う場合は、REGEXP_LIKEの方がいいかもね。
正規表現のパターンが複数回マッチするような割と大きめのデータでマッチした回数を調べたいときには便利かもね。
abcabcはabcが2回マッチしていることがわかる。
「指定したキーワードが10回以上出現する文書を検索したい」とかに使えるかも。処理速度はあまり期待できないかもだけど。
ここで、正規表現を「a.*c」に変えてマッチする様子を見てみようと思う。先ほどはメタ文字なしのabcにマッチするデータを検索したのだが、a.*cにするとどうなるかやってみようということである。多分マッチするデータが増えるはず。
予想通り、abc、abcabcに加えagcもマッチするようになったわけだが、マッチする回数がなんかおかしいような。
abcとagcはそれそのものしかないので、1回の出現回数となる。しかし、abcabcはa.*cが2回出現しているのでは?現にabcを指定した前の例では出現回数が2となっている。
なんかバグってる?
いえそんなことはないのである。
正規表現ではロンゲストマッチというマッチング(検索)処理が行われる。ロンゲストはlongの最大級(long longer longest)で一番長いを意味する。
abcabcには、a.*cにマッチする部分文字列が一見するとふたつあるように思えるが、abcの部分にもマッチするし、abcabcの全体でもマッチする。どちらもaで始まりcで終わっているからね。
先ほど述べたように正規表現はロンゲストマッチでマッチング処理を行うので、より長い方の結果が優先されることになる。
なので、regexp_countの結果も1になるわけである。
実は私も良く知らなかったのだが、ロンゲストマッチではなくショーテストマッチに変更できるとのこと。ロンゲストマッチはよく聞くのだが、ショーテストマッチ(最短一致)なんてあまり聞かんぞ。
メタ文字*は、0回以上の繰り返しを意味する。この繰り返しを意味するメタ文字には*の他+や{n}といったものもある。これらの繰り返しを意味するメタ文字に?を付けると最短一致になるというのである。
ここで整理のため繰り返しを意味するメタ文字をまとめておく。
では実際にやってみよう。前例の正規表現を「a.*?c」にしてみる。
確かにマッチングの様子が変わった。
正確には最短ではなく、最短最左になるみたいだが、ネストしているような特殊な場合だけ期待した通りにならないようなので、?を付ければ最短一致と覚えておけば良いであろう。
REGEXP_COUNTは、Oracleの他、DB2でも使用できる。PostgreSQL、MySQLでは使用できない。
次に紹介する3番目の正規表現関数は、REGEXP_INSTRである。
RDBMSにはREGEXP無しの正規表現に対応していない、INSTR関数が古くから存在している。INSTR関数は文字列の中から文字列を検索する関数である。例えば以下のように使用する。
INSTRは部分文字列を検索して最初に見つかった部分の桁数を戻す。「abc」の中から「bc」を検索すると、2文字目に見つかるので2が結果として得られている。
正規表現でa.*cと条件を付けているので、「agc」もマッチして行が返されるが、INSTRでは正規表現が使用できないので、bcが見つからず結果は0となっている。
REGEXP_INSTRはINSTRと同様に文字列中から文字列を検索するが、正規表現を与えることが可能。さっそく上記のINSTRの例をREGEXP_INSTRに変えてみよう。
REGEXP_INSTRに変更するとともに、正規表現パターンも条件式と同じ「a.*c」に変えてみた。agcについてもちゃんとヒットしていることがわかる。
REGEXP_INSTR関数では最初に見つけた部分文字列の位置を文字数で戻すことに注意しなければならない。JavaScriptにおけるmatchメソッドのように複数の結果が戻されることはない。ヒットする部分文字列が複数回出現するような場合は、regexp_instrの第4引数で出現回数を都度指定すれば良い。全体の出現回数はregexp_countで取得可能。
regexp_instr関数での引数は最大で7個まで指定が可能。最初の4つまではinstrとほとんど同じで、第2引数の検索する文字列で正規表現が使えるかどうかの違い。第5引数からregexp_instrで拡張された部分になる。
何番目に出現するものなのかの指定は第4引数なので、instr関数でも指定可能である。
まぁやってみればなんとなくわかるでしょう。
最短マッチにしないとabcabcが2回マッチしないので、a.*?cに変更している。select句で3つのフィールドを用意。最初がa列の内容、次が1回目の検索結果、最後が2回目の検索結果。abcabcでは2回目の検索結果が4文字目であることがわかる。
検索して見つからない場合は0が戻ってくる。マッチする箇所を全部処理したい時に、regexp_countで個数を取得しておいてその分ループをまわす、でも良いし、regexp_instrの第4引数にカウンタとなるループ変数を与えて戻りが0になるまで繰り返す、という感じでも実装できる。
REGEXP_INSTRは、Oracleの他、DB2、MySQLでも使用できる。PostgreSQLでは使用できない。
さて、次に紹介するのはREGEXP_REPLACE関数である。こちらもINSTRと同じように、正規表現に対応していないREPLACE関数が存在する。REGEXP_REPLACE関数、REPLACE関数はどちらも文字列置換を行う関数である。REGEXP_REPLACEとREPLACEの違いは正規表現を使って検索ができるかどうかである。
REPLACE関数の引数は全部で最低3つ指定する必要がある。
対象となる元の文字列、置換前の検索を行う文字列、置換後の文字列の3つである。
正規表現対応のREGEXP_REPLACE関数には第2引数(置換前の検索を行う文字列)と第3引数(置換後の文字列)に正規表現を使用することができる。
置換後の文字列に正規表現を使うといってもどう使えば良いのかピンと来ないかも知れない。まぁ読み進めてもらえれば理解できると思うので、まずは簡単な例から見てみよう。
先頭のaを大文字のAに文字列置換してみた。正規表現に対応していないREPLACE関数だと、abcabcがAbcAbcに置換されることになる。
次に、置換後の文字列にメタ文字を使った例を見てみよう。
正規表現がムズくなってしまった。なんか括弧ばかり付いてしまったし、謎の記号だらけである。申し訳ない。
ここで注目すべきは\-である。-は正規表現のメタ文字の一種なので、\を付けることでエスケープして-そのものを意味するようにしてある。データを見ると「0120-PMC」といったデータに-が含まれているので、\-でここにマッチすると考えてOK(\が¥と表示される環境もあるので注意)。
置換後の結果を見ると-が含まれる「0120-PMC」のデータだけ置換されていることがわかる。
\-の左右に任意の文字列を意味する.*が付いており、それが()で囲まれている感じになっている。この括弧はグループ化の指定でメタ文字の1種であるため実際のデータに(や)が含まれる必要はない。「0120-PMC」のデータでも括弧は含んでいない。
ここでの正規表現はバックスラッシュで-がエスケープされていること。()によるグループがふたつ存在することが難しく感じられる要因であろう。
さて、置換後の文字列に注目してみよう。第3引数には置換後の文字列を指定する。指定された文字列に置き換わるわけなのだが、ここに正規表現のメタ文字を使うことができる。メタ文字と言っても、*や.ではなく、\1や\2という感じのバックスラッシュに続く数字で構成されるメタ文字となる(MySQLでは\ではなく$を使用)。
バックスラッシュに続く数字が意味するのは、グループの番号である。ここでの正規表現にはグループがふたつ存在している。それらのグループを順番に\1、\2と表すことができるのである。
.*は任意の文字列を意味するので、マッチング処理の結果どんな文字列にもなり得る。abcでもagcでも123でもよいわけである。
間に-があるので、この部分は譲れない。マッチングしないと置換対象にならない。例にしているデータだと「0120-PMC」しかヒットしないことになる。
0120-PMCだけを例にしてどのようにマッチングされるかを見てみると...
みたいな感じになる。
-を挟んで、左側の0120が\1になり、右側のPMCが\2に対応することになる。置換後の文字列指定で\2 \1と順番を逆にしているので、「PMC 0120」と置換されるのである。
REGEXP_REPLACEは、Oracleの他、DB2、PostgreSQL、MySQLでも使用できる。
さて、最後に紹介するのはREGEXP_SUBSTR関数である。こちらも同じように、正規表現に対応していないSUBSTR関数が存在する。INSTRが文字列検索してその位置を戻すのに対してSUBSTRは部分文字列を返す。
その違いだけなので、さらっと例を上げるだけにしておく。
REGEXP_SUBSTRは、Oracleの他、DB2でも使用できる。
RDBMSにおける正規表現(REGEXP)
Proxmox ZFSでRAIDZ【M.2 SATA変換】
我が家にも10ギガの時代がやってきた 【NETGEAR GS110EMX購入】
余ったDualポートEthernetカードとM.2 SSD【4ポートでLAG】
ラックマウント用のPCケースを導入した話
3チャネルボンディング(チーミング) 3ギガ出るかやってみた
TP-LinkのWi-Fi 6ルーターを購入した話【前編】
![[改訂第4版]SQLポケットリファレンス](https://images-fe.ssl-images-amazon.com/images/I/518GTfGD0aL._SL160_.jpg "[改訂第4版]SQLポケットリファレンス")
サイト内を検索
まずは、Oracle23cでやってみる。
Oracle23cはProxmoxのVMにOracle Linux 8を入れてその中にOracle23cをインストールしている。
REGEXP_LIKE
最初に紹介するのはREGEXP_LIKEである。
これはSQL標準のLIKEによるあいまい検索を「正規表現」でやる感じの関数である。
以下の例を見て貰えればわかりやすいであろう。
select a from foo where regexp_like(a,'^a.*'); a ------ abc agc abcabc
regexp_likeの第一引数には元となる文字列を入れる。上記の例の場合は、fooテーブルのa列を指定している。ちなみにfooテーブルのa列には以下のようなデータが格納されている。
select a from foo; a ---------- abc 123 agc 8139too 0120-PMC abcabc
このデータの中から正規表現「^a.*」にマッチするものだけを検索して表示させるのがregexp_likeを使った先の例文である。
regexp_likeの第一引数には元となる文字列を入れ、続く第二引数には正規表現で示した文字列を与える。
regexp_likeの機能は、第一引数で与えられた文字列の中に第二引数の正規表現で示された文字列が存在していれば真を返し、存在しなければ偽を返す、といったものになる。
第二引数の正規表現の部分にメタ文字を含んでいなくてもかまわない。これがLIKEとちょっと違う点なのでハマりポイントかも知れない。
例えばLIKEで「文字1を含むもの」といった検索をしようとしたら、以下のようにすると思う。
select a from foo where a like '%1%'; a ---------- 123 8139too 0120-PMC
これをregexp_likeでやろうとしたら、以下のようにできる。
select a from foo where regexp_like(a, '1'); a ---------- 123 8139too 0120-PMC
もちろんメタ文字を含んでもOK
select a from foo where regexp_like(a, '.*1.*'); a ---------- 123 8139too 0120-PMC
LIKEでは「何々を含む」といった検索を行う場合、何々の前後にメタ文字%を付け、何々の前後が任意の文字列であっても検索に引っかかるようにしないといけない。
REGEXP_LIKEではメタ文字を使うことなく、単に「何々」を指定すればOKで「何々」を含むかどうかでヒットするのである。
前方一致と後方一致
あいまい検索の場合、その検索のやり方にいくつかパターンがあり、前方一致、後方一致などがある。「何々を含む」といった検索は部分一致になる。
前方一致は、「何々から始まる」という検索方法で、LIKEでやるなら以下のように後ろに%を付けると前方一致になる。
select a from foo where a like '1%'; a ---------- 123
1から始まるものを検索。
正規表現の場合、「1.*」としても先頭の文字が1でない場合もヒットしてしまうので、先頭を意味するメタ文字である^を使って「^1.*」としなければならない。
^を付けずに実行すると...
select a from foo where regexp_like(a,'1.*'); a ---------- 123 8139too 0120-PMC
先頭が1でないものまでヒットする。
select a from foo where regexp_like(a,'^1.*'); a ---------- 123
先頭を意味するメタ文字^を加えて「^1.*」とすればLIKE '1%'と同じになる。
後方一致は逆に「何々で終わる」ものを検索する。LIKEでは「%1」とすれば良い。REGEXP_LIKEでは終わりを意味するメタ文字$を使って「.*1$」にすればOK。
合わせ技で「aで始まりcで終わる」という検索も可能。
LIKEなら「a%c」
REGEXP_LIKEなら「^a.*c$」
とすればOK。
何れかにマッチさせる
あいまい検索を行う際に「何々」または「うんたら」の両方を検索したいっていう場合もあるでしょう。SQL命令のOR条件を使うような場合である。
例のfooテーブルから「123」か「abc」を含むものを検索する時は次のようなSQL命令になるであろう。
select a from foo where a like '%123%' or a like '%abc%'; a ---------- abc 123 abcabc
LIKEのメタ文字には「または」を意味するようなものが存在しない。正規表現にはグループ化という概念があり、グループのうち何れかとマッチすればOKといった検索が可能。そのため1回のREGEXP_LIKE呼び出しで上記の「123」か「abc」を含むものを検索するクエリを記述できる。
select a from foo where regexp_like(a, '(123|abc)'); a ---------- abc 123 abcabc
ほらね。できたでしょ。
グループは(で始まり、)で終わる。グループの中はマッチさせたい文字列を列挙するが区切りを|で表記する。3つ以上でもかまわない。
グループ内の文字列にメタ文字を含んでいても良い。
select a from foo where regexp_like(a, '(123|a.*c)'); a ---------- abc 123 agc abcabc
123かa.*cにマッチするものを検索。
このグループ化の機能は「大した機能じゃない」と思われるかも知れないが、置換や抽出とかやり出すと重宝する。置換についてはREGEXP_REPLACE関数で解説しようと思う。
REGEXP_LIKEは、Oracleの他、DB2、MySQLでも使用できる。PostgreSQLでは~演算子で正規表現によるパターンマッチングが可能。
REGEXP_COUNT
次に紹介する正規表現関数は、REGEXP_COUNTである。正規表現関数は頭がREGEXPとなっている。
REGEXP_COUNTは元の文字列内に正規表現とマッチする部分文字列が、いくつあるのかを数えて戻す関数。REGEXP_LIKEがマッチする/しないを真偽で返すことに対して、REGEXP_COUNTはマッチしないのであれば0、マッチするのであればその回数を戻すため、1以上の数値となる。
select a from foo where regexp_count(a, '(123|abc)') >= 1; a ---------- abc 123 abcabc
WHERE条件で使う場合は、REGEXP_LIKEの方がいいかもね。
正規表現のパターンが複数回マッチするような割と大きめのデータでマッチした回数を調べたいときには便利かもね。
select a, regexp_count(a, 'abc') from foo where regexp_like(a, 'abc'); a regexp_count ---------- ------------ abc 1 abcabc 2
abcabcはabcが2回マッチしていることがわかる。
「指定したキーワードが10回以上出現する文書を検索したい」とかに使えるかも。処理速度はあまり期待できないかもだけど。
ロンゲストマッチ
ここで、正規表現を「a.*c」に変えてマッチする様子を見てみようと思う。先ほどはメタ文字なしのabcにマッチするデータを検索したのだが、a.*cにするとどうなるかやってみようということである。多分マッチするデータが増えるはず。
select a, regexp_count(a, 'a.*c') from foo where regexp_like(a, 'a.*c'); a regexp_count ---------- ------------ abc 1 agc 1 abcabc 1
予想通り、abc、abcabcに加えagcもマッチするようになったわけだが、マッチする回数がなんかおかしいような。
abcとagcはそれそのものしかないので、1回の出現回数となる。しかし、abcabcはa.*cが2回出現しているのでは?現にabcを指定した前の例では出現回数が2となっている。
なんかバグってる?
いえそんなことはないのである。
正規表現ではロンゲストマッチというマッチング(検索)処理が行われる。ロンゲストはlongの最大級(long longer longest)で一番長いを意味する。
abcabcには、a.*cにマッチする部分文字列が一見するとふたつあるように思えるが、abcの部分にもマッチするし、abcabcの全体でもマッチする。どちらもaで始まりcで終わっているからね。
先ほど述べたように正規表現はロンゲストマッチでマッチング処理を行うので、より長い方の結果が優先されることになる。
なので、regexp_countの結果も1になるわけである。
実は私も良く知らなかったのだが、ロンゲストマッチではなくショーテストマッチに変更できるとのこと。ロンゲストマッチはよく聞くのだが、ショーテストマッチ(最短一致)なんてあまり聞かんぞ。
メタ文字*は、0回以上の繰り返しを意味する。この繰り返しを意味するメタ文字には*の他+や{n}といったものもある。これらの繰り返しを意味するメタ文字に?を付けると最短一致になるというのである。
ここで整理のため繰り返しを意味するメタ文字をまとめておく。
| 量指定子 | 最短一致 | メタ文字の意味 |
|---|---|---|
| * | *? | 0回以上の繰り返し |
| + | +? | 1回以上の繰り返し |
| ? | ?? | あるかないかのどちらか |
| {N} | N回の繰り返し | |
| {min,} | {min,}? | min回以上のの繰り返し |
| {,max} | {,max}? | max回以下の繰り返し |
| {min,max} | {min,max}? | min回以上でmax回以下の繰り返し |
では実際にやってみよう。前例の正規表現を「a.*?c」にしてみる。
select a, regexp_count(a, 'a.*?c') from foo where regexp_like(a, 'a.*?c'); a regexp_count ---------- ------------ abc 1 agc 1 abcabc 2
確かにマッチングの様子が変わった。
正確には最短ではなく、最短最左になるみたいだが、ネストしているような特殊な場合だけ期待した通りにならないようなので、?を付ければ最短一致と覚えておけば良いであろう。
REGEXP_COUNTは、Oracleの他、DB2でも使用できる。PostgreSQL、MySQLでは使用できない。
REGEXP_INSTR
次に紹介する3番目の正規表現関数は、REGEXP_INSTRである。
RDBMSにはREGEXP無しの正規表現に対応していない、INSTR関数が古くから存在している。INSTR関数は文字列の中から文字列を検索する関数である。例えば以下のように使用する。
select a, instr(a, 'bc') from foo where regexp_like(a, 'a.*c'); a instr ---------- ----- abc 2 agc 0 abcabc 2
INSTRは部分文字列を検索して最初に見つかった部分の桁数を戻す。「abc」の中から「bc」を検索すると、2文字目に見つかるので2が結果として得られている。
正規表現でa.*cと条件を付けているので、「agc」もマッチして行が返されるが、INSTRでは正規表現が使用できないので、bcが見つからず結果は0となっている。
REGEXP_INSTRはINSTRと同様に文字列中から文字列を検索するが、正規表現を与えることが可能。さっそく上記のINSTRの例をREGEXP_INSTRに変えてみよう。
select a, regexp_instr(a, 'a.*c') from foo where regexp_like(a, 'a.*c'); a regexp_instr ---------- ------------ abc 1 agc 1 abcabc 1
REGEXP_INSTRに変更するとともに、正規表現パターンも条件式と同じ「a.*c」に変えてみた。agcについてもちゃんとヒットしていることがわかる。
REGEXP_INSTR関数では最初に見つけた部分文字列の位置を文字数で戻すことに注意しなければならない。JavaScriptにおけるmatchメソッドのように複数の結果が戻されることはない。ヒットする部分文字列が複数回出現するような場合は、regexp_instrの第4引数で出現回数を都度指定すれば良い。全体の出現回数はregexp_countで取得可能。
regexp_instr関数での引数は最大で7個まで指定が可能。最初の4つまではinstrとほとんど同じで、第2引数の検索する文字列で正規表現が使えるかどうかの違い。第5引数からregexp_instrで拡張された部分になる。
何番目に出現するものなのかの指定は第4引数なので、instr関数でも指定可能である。
まぁやってみればなんとなくわかるでしょう。
select a, regexp_instr(a, 'a.*?c') instr, regexp_instr(a, 'a.*?c', 1, 2) instr2 from foo where regexp_like(a, 'a.*?c'); a instr instr2 ---------- -------- --------- abc 1 0 agc 1 0 abcabc 1 4
最短マッチにしないとabcabcが2回マッチしないので、a.*?cに変更している。select句で3つのフィールドを用意。最初がa列の内容、次が1回目の検索結果、最後が2回目の検索結果。abcabcでは2回目の検索結果が4文字目であることがわかる。
検索して見つからない場合は0が戻ってくる。マッチする箇所を全部処理したい時に、regexp_countで個数を取得しておいてその分ループをまわす、でも良いし、regexp_instrの第4引数にカウンタとなるループ変数を与えて戻りが0になるまで繰り返す、という感じでも実装できる。
REGEXP_INSTRは、Oracleの他、DB2、MySQLでも使用できる。PostgreSQLでは使用できない。
REGEXP_REPLACE
さて、次に紹介するのはREGEXP_REPLACE関数である。こちらもINSTRと同じように、正規表現に対応していないREPLACE関数が存在する。REGEXP_REPLACE関数、REPLACE関数はどちらも文字列置換を行う関数である。REGEXP_REPLACEとREPLACEの違いは正規表現を使って検索ができるかどうかである。
REPLACE関数の引数は全部で最低3つ指定する必要がある。
対象となる元の文字列、置換前の検索を行う文字列、置換後の文字列の3つである。
正規表現対応のREGEXP_REPLACE関数には第2引数(置換前の検索を行う文字列)と第3引数(置換後の文字列)に正規表現を使用することができる。
置換後の文字列に正規表現を使うといってもどう使えば良いのかピンと来ないかも知れない。まぁ読み進めてもらえれば理解できると思うので、まずは簡単な例から見てみよう。
select a, regexp_replace(a, '^a', 'A') replace from foo; a replace ---------- ---------- abc Abc 123 123 agc Agc 8139too 8139too 0120-PMC PMC 0120 abcabc Abcabc
先頭のaを大文字のAに文字列置換してみた。正規表現に対応していないREPLACE関数だと、abcabcがAbcAbcに置換されることになる。
次に、置換後の文字列にメタ文字を使った例を見てみよう。
select a, regexp_replace(a, '(.*)\-(.*)', '\2 \1') rrep from foo; a rrep ---------- ---------- abc abc 123 123 agc agc 8139too 8139too 0120-PMC PMC 0120 abcabc abcabc
正規表現がムズくなってしまった。なんか括弧ばかり付いてしまったし、謎の記号だらけである。申し訳ない。
ここで注目すべきは\-である。-は正規表現のメタ文字の一種なので、\を付けることでエスケープして-そのものを意味するようにしてある。データを見ると「0120-PMC」といったデータに-が含まれているので、\-でここにマッチすると考えてOK(\が¥と表示される環境もあるので注意)。
置換後の結果を見ると-が含まれる「0120-PMC」のデータだけ置換されていることがわかる。
\-の左右に任意の文字列を意味する.*が付いており、それが()で囲まれている感じになっている。この括弧はグループ化の指定でメタ文字の1種であるため実際のデータに(や)が含まれる必要はない。「0120-PMC」のデータでも括弧は含んでいない。
ここでの正規表現はバックスラッシュで-がエスケープされていること。()によるグループがふたつ存在することが難しく感じられる要因であろう。
さて、置換後の文字列に注目してみよう。第3引数には置換後の文字列を指定する。指定された文字列に置き換わるわけなのだが、ここに正規表現のメタ文字を使うことができる。メタ文字と言っても、*や.ではなく、\1や\2という感じのバックスラッシュに続く数字で構成されるメタ文字となる(MySQLでは\ではなく$を使用)。
バックスラッシュに続く数字が意味するのは、グループの番号である。ここでの正規表現にはグループがふたつ存在している。それらのグループを順番に\1、\2と表すことができるのである。
(.*)\-(.*) ↑ ↑ \1 \2
.*は任意の文字列を意味するので、マッチング処理の結果どんな文字列にもなり得る。abcでもagcでも123でもよいわけである。
間に-があるので、この部分は譲れない。マッチングしないと置換対象にならない。例にしているデータだと「0120-PMC」しかヒットしないことになる。
0120-PMCだけを例にしてどのようにマッチングされるかを見てみると...
0120-PMC
↑ ↑ ↑
(.*)¥-(.*)
↑ ↑
\1 \2
みたいな感じになる。
-を挟んで、左側の0120が\1になり、右側のPMCが\2に対応することになる。置換後の文字列指定で\2 \1と順番を逆にしているので、「PMC 0120」と置換されるのである。
REGEXP_REPLACEは、Oracleの他、DB2、PostgreSQL、MySQLでも使用できる。
REGEXP_SUBSTR
さて、最後に紹介するのはREGEXP_SUBSTR関数である。こちらも同じように、正規表現に対応していないSUBSTR関数が存在する。INSTRが文字列検索してその位置を戻すのに対してSUBSTRは部分文字列を返す。
その違いだけなので、さらっと例を上げるだけにしておく。
select a, regexp_substr(a, 'a.*?c') substr, regexp_substr(a, 'a.*?c', 1, 2) substr2 from foo where regexp_like(a, 'a.*?c'); a substr substr2 ---------- -------- --------- abc abc agc agc abcabc abc abc
REGEXP_SUBSTRは、Oracleの他、DB2でも使用できる。
関連記事
ProxmoxにOracle23cを入れてみる【OL9には入らない】RDBMSにおける正規表現(REGEXP)
Proxmox ZFSでRAIDZ【M.2 SATA変換】
我が家にも10ギガの時代がやってきた 【NETGEAR GS110EMX購入】
余ったDualポートEthernetカードとM.2 SSD【4ポートでLAG】
ラックマウント用のPCケースを導入した話
3チャネルボンディング(チーミング) 3ギガ出るかやってみた
TP-LinkのWi-Fi 6ルーターを購入した話【前編】
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2017/02/18
- メディア: 単行本(ソフトカバー)
サイト内を検索
ProxmoxにOracle23cを入れてみる【OL9には入らない】 [SQLポケリ]
えーと今回はRDBMSにおける正規表現をやろうかと思ったのだが、Oracle入れないと動作検証できないなぁ... Oracle Cloudしばらく使ってないからデータベースインスタンス停止しちゃったみたいだし。

proxmoxが動いてるのだからVirtual PCでOracle23c動かせばいい感じなんじゃないか?
ということで、proxmoxにOracle23c導入するのを頑張ってみよう。
最新のOracleのバージョンは23cである。出たばっかなのか?その前は19cか。proxmox用のLXCでOracleがあれば良いのだが...そんなテンプレートはないか。残念。
Oracleは開発者向けに無料でOracleを使えるようにしてくれている。
https://www.oracle.com/jp/database/free/download/
ファイルが3つあるぞ。
OL8はOracle Linuxだな。RHEL8はRedHat 8でしょ。RedHatは有料なので、OL8を用意しないとダメか。
まずは、proxmoxにOL8を入れてみるか。OracleのサイトからISOファイルをダウンロードしなくては。
https://yum.oracle.com/oracle-linux-isos.html
OL9が最新みたいだけど、8の方がいいのかなぁ?新しい方がいいか。
ファイル容量が10G近くあるので、proxmoxのコンソールからダウンロードしてサーバー側でやらせる。
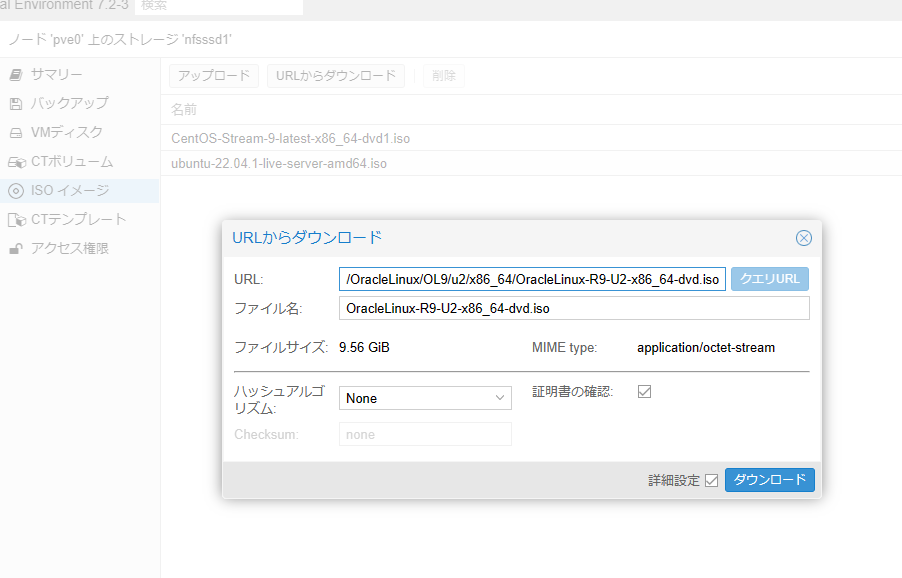
ISOファイルが入手できたら、VMを作る。
名前は「OracleLinux9」だな。
先ほどダウンロードしたISOファイルを仮想CD/DVDに入れて立ち上げたいので、ストレージとISOイメージを選択。
で、次へ。
グラフィックスはどうなのかなぁ。必要?
SCSIコントローラーは要るかもだけどちょっとよくわからないので、デフォルトのまま、次へ。
ディスクサイズは32Gだとちょっと不安。64Gに増やしておくか。
デバイスはNFSマウントできるSSDのZFSにする。
キャッシュはあった方が高速だが信頼性は×。試験的にやるだけなので、Write backで行く。
CPUのコアは2個にしておくかな。
種別はhostにしておく。
メモリは最小構成にしたいところ。4Gで行くか、8Gにするか。2Gじゃ足りないかも。
どうする。4Gで行ってみるか。
ネットワークは普通にブリッジ作っておけばOK?
これで行ってみよう。
完了ボタンのクリックでVM:OracleLinux9が作成された。
起動してみる。
コンソールを開いてみると...
なんか出たじゃん。
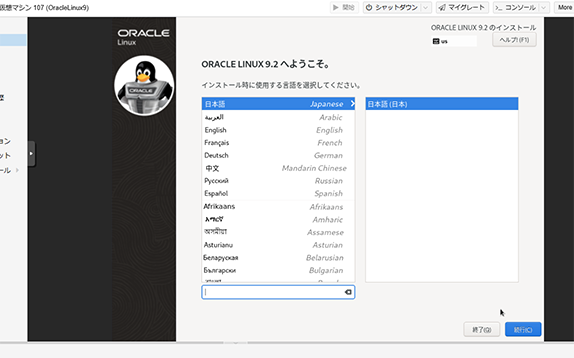
ORACLE LINUX 9.2のインストール キター
CentOSと似た感じのインストーラーだな。
インストール先のストレージとrootパスワードを設定したら「インストールの開始」でゴー。
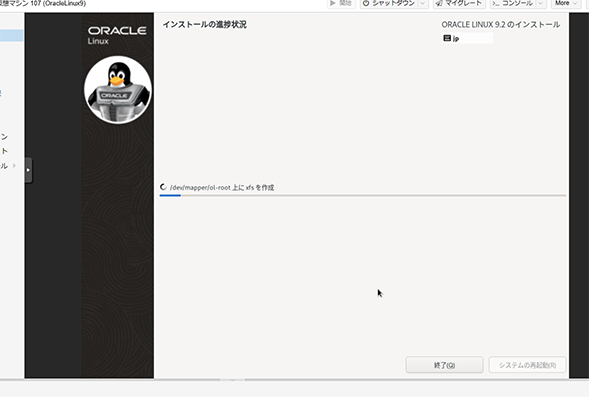
しばらくゲームして待つ。
なんかインストールできたので、Oracle23cのインストールに移行する。
OracleLinuxのVMでFirefoxを起動して、Oracle23cをダウンロードしてくる。
dnfコマンドでrpmパッケージをインストールすればよいらしいのだが、依存関係でダメ。OL8じゃないとインストールできないのかも。--nobestを付けるとバージョン違いはなんとかしれてくれるみたいなので、やってみる。
ダメじゃん。
OL8入れなおすか。
とほほ。
OL8のISOファイルダウンロードからやり直し。
ようやくdnfコマンドのところまでやり直しできた。dnf -y updateもやったのでかなり時間がかかる。
本体を入れる前に、preinstallの方を入れる必要がある。OL9の時はここでもう、つまずいた。SSLのバージョンが合わないと...
preinstallのインストールはすぐに終了する。OL8ならSSLのバージョン違いはないようである。やれやれ。
本体は1.6Gもあるのでそれなりに時間がかかる。いつの時代でもOracleのインストールって時間がかかるなぁ。
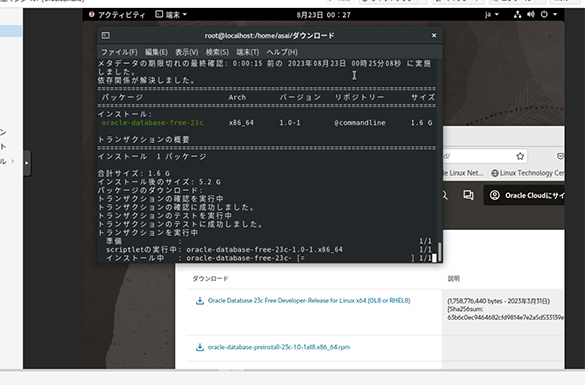
RPMのインストールは終わったのだが... この後どうするの?
なんかめちゃ大変。
インストールマニュアルを読むと...
で何かをインストール
で有効化。デーモンが立ち上がるのか?
でスクリプトを動かすと、アカウントにパスワードを付けろと...
パスワードのルールが厳しくなる一方でパスワード管理が大変なのだが...
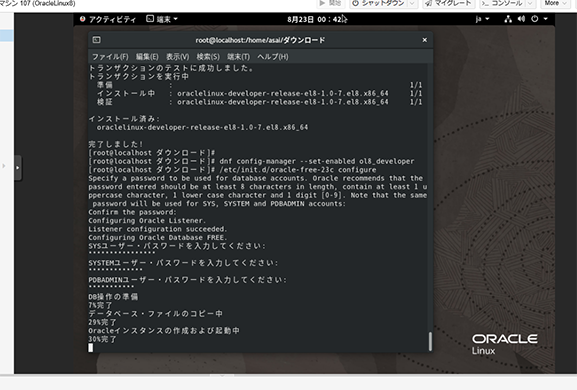
データベースの作成中になった。そうそう、こっからがまた長いのよねOracleって。
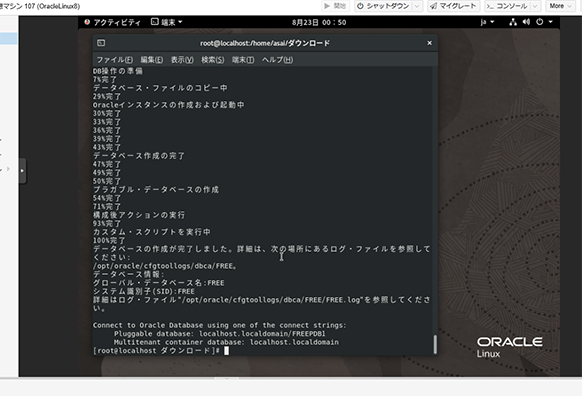
なんか成功したっぽい。
sqlplusで接続するんだろうけど続きはまた。
我が家にも10ギガの時代がやってきた 【NETGEAR GS110EMX購入】
余ったDualポートEthernetカードとM.2 SSD【4ポートでLAG】
ラックマウント用のPCケースを導入した話
3チャネルボンディング(チーミング) 3ギガ出るかやってみた
TP-LinkのWi-Fi 6ルーターを購入した話【前編】
BuffaloのWiFiルータはブリッジモードとルータモードでIPアドレスが異なるのでハマった
Ethernetのボンディング Linuxのサーバーマシンにbond0インターフェースを作成


 204Pin Mac 対応 SP016GBSTU160N22")
 288Pin 1.2V CL19 SP016GBLFU266B22")
サイト内を検索
proxmoxが動いてるのだからVirtual PCでOracle23c動かせばいい感じなんじゃないか?
ということで、proxmoxにOracle23c導入するのを頑張ってみよう。
最新のOracleのバージョンは23cである。出たばっかなのか?その前は19cか。proxmox用のLXCでOracleがあれば良いのだが...そんなテンプレートはないか。残念。
Oracleは開発者向けに無料でOracleを使えるようにしてくれている。
https://www.oracle.com/jp/database/free/download/
ファイルが3つあるぞ。
OL8はOracle Linuxだな。RHEL8はRedHat 8でしょ。RedHatは有料なので、OL8を用意しないとダメか。
まずは、proxmoxにOL8を入れてみるか。OracleのサイトからISOファイルをダウンロードしなくては。
https://yum.oracle.com/oracle-linux-isos.html
OL9が最新みたいだけど、8の方がいいのかなぁ?新しい方がいいか。
ファイル容量が10G近くあるので、proxmoxのコンソールからダウンロードしてサーバー側でやらせる。
VMの作成
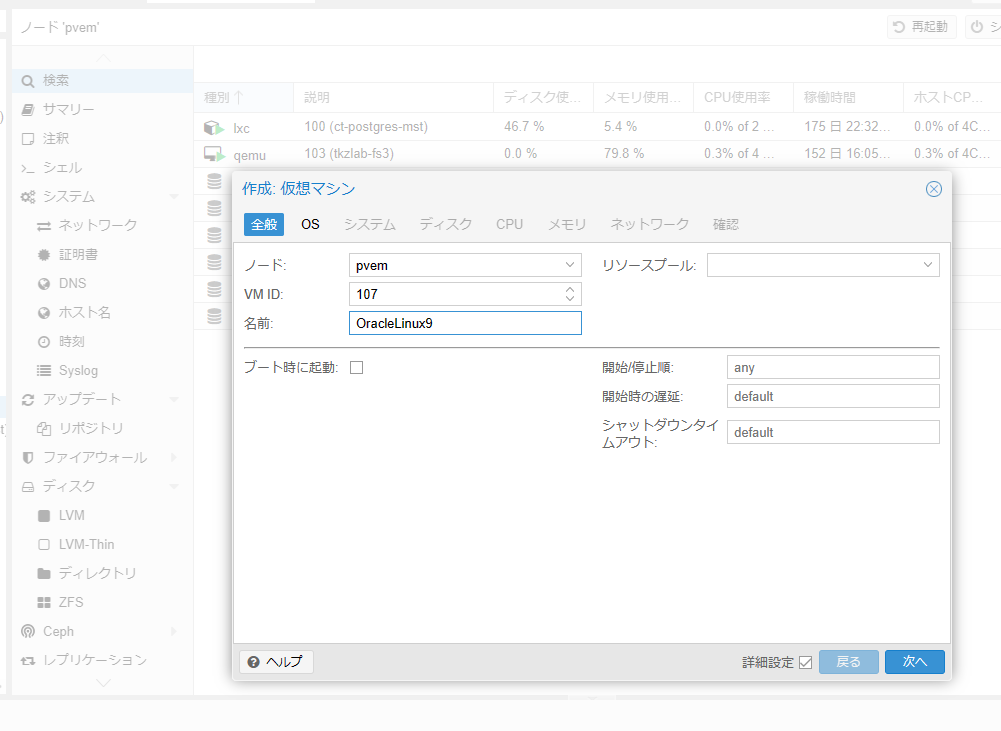
ISOファイルが入手できたら、VMを作る。
名前は「OracleLinux9」だな。
先ほどダウンロードしたISOファイルを仮想CD/DVDに入れて立ち上げたいので、ストレージとISOイメージを選択。
で、次へ。
グラフィックスはどうなのかなぁ。必要?
SCSIコントローラーは要るかもだけどちょっとよくわからないので、デフォルトのまま、次へ。
ディスクサイズは32Gだとちょっと不安。64Gに増やしておくか。
デバイスはNFSマウントできるSSDのZFSにする。
キャッシュはあった方が高速だが信頼性は×。試験的にやるだけなので、Write backで行く。
CPUのコアは2個にしておくかな。
種別はhostにしておく。
メモリは最小構成にしたいところ。4Gで行くか、8Gにするか。2Gじゃ足りないかも。
どうする。4Gで行ってみるか。
ネットワークは普通にブリッジ作っておけばOK?
これで行ってみよう。
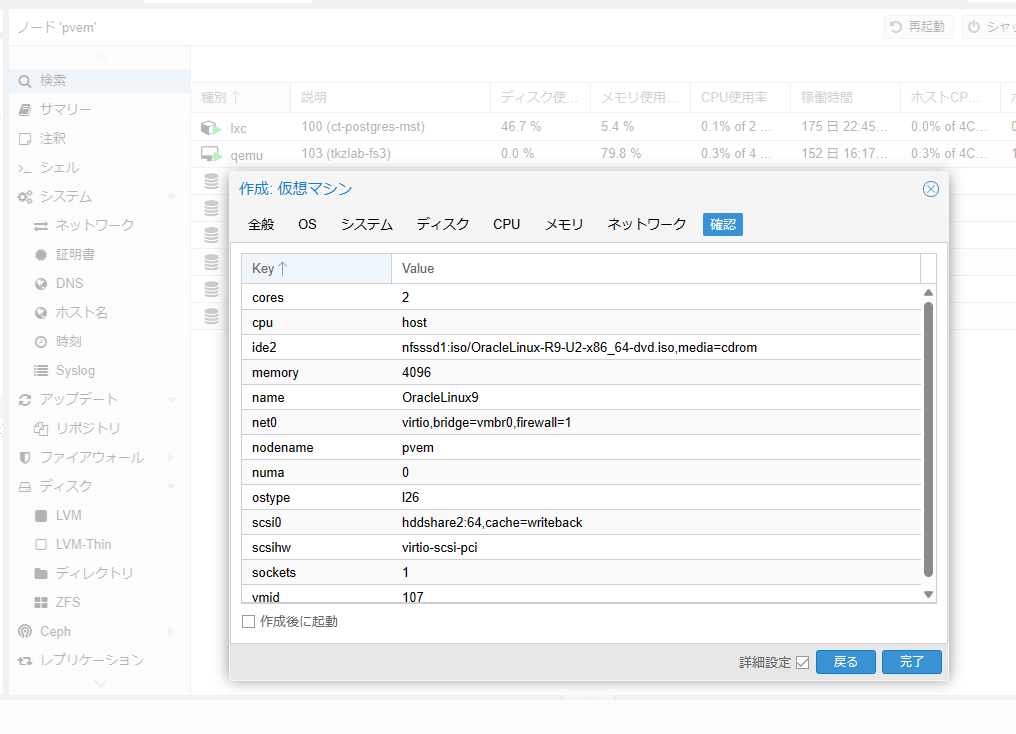
完了ボタンのクリックでVM:OracleLinux9が作成された。
起動してみる。
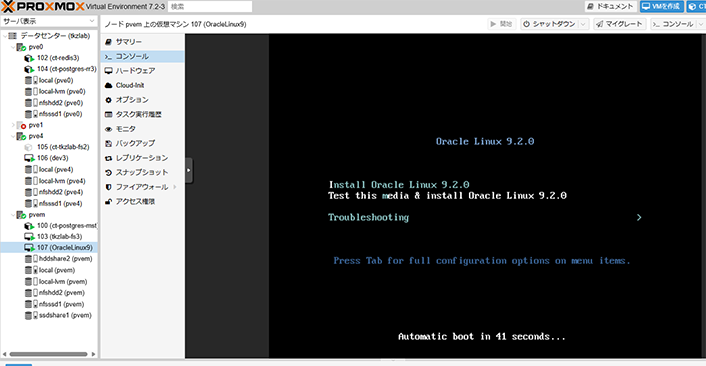
コンソールを開いてみると...
なんか出たじゃん。
ORACLE LINUX 9.2のインストール キター
CentOSと似た感じのインストーラーだな。
インストール先のストレージとrootパスワードを設定したら「インストールの開始」でゴー。
しばらくゲームして待つ。
なんかインストールできたので、Oracle23cのインストールに移行する。
Oracle23cのインストール
OracleLinuxのVMでFirefoxを起動して、Oracle23cをダウンロードしてくる。
dnfコマンドでrpmパッケージをインストールすればよいらしいのだが、依存関係でダメ。OL8じゃないとインストールできないのかも。--nobestを付けるとバージョン違いはなんとかしれてくれるみたいなので、やってみる。
ダメじゃん。
OL8入れなおすか。
とほほ。
OL8のISOファイルダウンロードからやり直し。
ようやくdnfコマンドのところまでやり直しできた。dnf -y updateもやったのでかなり時間がかかる。
本体を入れる前に、preinstallの方を入れる必要がある。OL9の時はここでもう、つまずいた。SSLのバージョンが合わないと...
preinstallのインストールはすぐに終了する。OL8ならSSLのバージョン違いはないようである。やれやれ。
本体は1.6Gもあるのでそれなりに時間がかかる。いつの時代でもOracleのインストールって時間がかかるなぁ。
RPMのインストールは終わったのだが... この後どうするの?
なんかめちゃ大変。
インストールマニュアルを読むと...
dnf install -y oraclelinux-developer-release-el8
で何かをインストール
dnf config-manager --set-enabled ol8_developer
で有効化。デーモンが立ち上がるのか?
/etc/init.d/oracle-free-23c configure
でスクリプトを動かすと、アカウントにパスワードを付けろと...
パスワードのルールが厳しくなる一方でパスワード管理が大変なのだが...
データベースの作成中になった。そうそう、こっからがまた長いのよねOracleって。
なんか成功したっぽい。
sqlplusで接続するんだろうけど続きはまた。
関連記事
Proxmox ZFSでRAIDZ【M.2 SATA変換】我が家にも10ギガの時代がやってきた 【NETGEAR GS110EMX購入】
余ったDualポートEthernetカードとM.2 SSD【4ポートでLAG】
ラックマウント用のPCケースを導入した話
3チャネルボンディング(チーミング) 3ギガ出るかやってみた
TP-LinkのWi-Fi 6ルーターを購入した話【前編】
BuffaloのWiFiルータはブリッジモードとルータモードでIPアドレスが異なるのでハマった
Ethernetのボンディング Linuxのサーバーマシンにbond0インターフェースを作成
- 出版社/メーカー: サンワサプライ
- メディア: エレクトロニクス
NETGEAR Inc. JGS524E 【ライフタイム保証】 24ポート ギガビット アンマネージプラス・スイッチ JGS524E-200AJS
- 出版社/メーカー: ネットギア
- メディア: Personal Computers
シリコンパワー ノートPC用メモリ DDR3 1600 PC3-12800 8GB×2枚 (16GB) 204Pin Mac 対応 SP016GBSTU160N22
- 出版社/メーカー: シリコンパワー
- 発売日: 2012/09/01
- メディア: 付属品
シリコンパワー デスクトップPC用 メモリ DDR4 2666 PC4-21300 8GB x 2枚 (16GB) 288Pin 1.2V CL19 SP016GBLFU266B22
- 出版社/メーカー: シリコンパワー
- 発売日: 2018/07/27
- メディア: Personal Computers
サイト内を検索
RDBMSにおける正規表現(REGEXP) [SQLポケリ]
お盆休みはがっつりゲーム三昧であった。最近のPCゲームはなんかスゴイねぇ。
さて、久しぶりにデータベースネタをやってみようと思う。
正規表現ってプログラマならよく使うと思う。検索とかの時にね。
この間作った機密情報が入ったファイルの名前なんだっけか?えーと「secretほにゃらら」だったと思うのだが...
っていう時、エクスプローラーで「secret*」というように検索するよね?
*の部分がほにゃららに対応するので、secret_info.txtだったり、secret_image.jpgだったりが検索結果としてヒットする。
この*はワイルドカードとかメタ文字と呼ばれるもので、*の他にも色々種類があるのだが、RDBMSで標準的に使うことができるのは以下の2種類しかない。
%
_
なんとも寂しい感じである。
SQLを知らない人向けに簡単に説明すると、%が任意の文字列にマッチするワイルドカード。_は任意の1文字にマッチする。
でもってこれらの検索には「LIKE演算子」を使って条件式を書かないといけない。
まぁ、そんなに難しくはないでしょ?例を挙げてみると以下のような感じ。
SELECT file_name FROM file_list WHERE file_name LIKE 'secret%' file_name ----------------- secret_info.txt secret_image.jpg
冒頭のファイル名での検索をSQLでやってみた感じである。
でもって、メタ文字である%や_を使って表記した文字列(ここでは'secret%')が正規表現で記述したものなのか、というとそうではない。
正規表現、英語で言ったらRegular Expressionなのだが、ちゃんとした国際規格になっている。SQLのLIKEで使われるのは正規表現とは異なる独自規格なのである。
正規表現で任意の文字列を表記するには「.*」とする。*だけならエクスプローラーでもやるので馴染みがあるのだが、なんか.が付いてる。
この「.」が意味するものはSQL LIKEでの「_」と同じ。つまり任意の1文字とマッチする。
一方の「*」は何かというと0回以上の繰り返しを意味する。つまり、正規表現「.*」は「任意の1文字を0回以上繰り返したもの」という意味になる。
他にもSQL LIKEと正規表現の違いは多くあり、正規表現の方がはるかに大きな仕様となっていて、様々なマッチング処理が可能になっている。
REGEXP
RDBMSの種類にもよるのだが、正規表現が使えたり、使えなかったり、拡張モジュールを入れないと使えなかったり、とまぁいろいろあるのでちゃんと調べるついでに記事にしてみるか、というのが今回の趣旨となる。
RDBMSではREGEXP~という関数が使える場合がある。REGEXPはRegular Expressionの略。REGEXP~関数を追いかけていけば、RDBMSにおける正規表現対応状況が把握できるのではないかということでSQLポケリを引っ張り出してきたのである。
Oracleでの正規表現
まずは、Oracleさんである。結構前から正規表現でのマッチングはできたような気がする。正規表現を使うとメタ文字で表記した部分だけを取り出したり、置換したりすることが可能なのだが、OracleにはREGEXPから始まる関数が存在している。
REGEXP_COUNT
REGEXP_LIKE
REGEXP_INSTR
REGEXP_SUBSTR
SQLポケリ4版にはREGEXP_COUNTとREGEXP_LIKEのみが項として載っている(332ページと282ページ)。REGEXP_INSTRについてはINSTRのページに、REGEXP_INSTRもあるよ、と付け足されている。REGEXP_SUBSTRも同様。
SQL Serverでの正規表現
SQL Serverでは正規表現は全くダメ。使おうと思ったら自分で関数作って拡張しないとダメ。ただ、LIKEで使えるメタ文字が少しだけ多いのでそれでお茶を濁している感じかな。MS AccessもエンジンはSQL Serverと統合されちゃった感じなのでほとんど同じ状況。
そもそも、Windowsにはgrepがなかったからなぁ。正規表現を使いたかったらクライアント側でなんとかやってね、というスタンスなのかも。
DB2での正規表現
v11になってREGEXP~関数が使えるようになったらしいぞ。DB2はOracle互換とか言ってたから「Oracleにならえ」ということなんでしょう。普通に使えるようになるのは良いことだと思う。
SQLポケリ4版はv10までなので、REGEXPがらみは書いてない。
PostgreSQLでの正規表現
Postgresではいつの頃からかREGEXP関係の関数が使えるようになっている。まぁ、昔から~演算子で正規表現マッチングできていたからね。
オープンソース系はみなgrepの存在するプラットホームで動いていたから正規表現はお手の物という感じ。
MySQLでの正規表現
MySQLはOracleに引き取られたので、Oracleと同じようになってきている。REGEXPも同じように使えるみたい。
問題はMariaDBの方だが...検索してみると... なんだちゃんとあるじゃん。MySQLと互換性ありって言っているので問題なしかも。
SQLite
最後はSQLiteかな、オープンソースものは正規表現対応のものが多いのだが...
えーと前にもちょっと調べた気がしてきた。
SQLポケリ4版のREGEXP演算子(281ページ)には「拡張モジュールをロードする必要があります」って書いてある。
今現在のSQLiteのドキュメントを見るとREGEXP演算子が使えるみたいに書いてある。これはどこかで拡張モジュールを入れなくてもOKになった?のかなぁ...
ドキュメントにはregexp演算子はユーザー定義関数のregexpを呼び出すだけみたいな記載があるだけだな。
やっぱり拡張モジュールを入れないとダメなのかな。
とうことで大体の対応状況はわかった。REGEXP~関数に対応しているのは、以下のRDBMSである。
Oracle
DB2
PostgreSQL
MySQL/MariaDB
本日はここまで。
関連記事
SQLとJSON JSONデータをRDBに格納する
分析関数percentile_cont 中央値でノイズ除去
SQL分析関数 ROW_NUMBER RANK DENSE_RANK
SQL分析関数 FIRST_VALUE LAST_VALUE NTH_VALUE LAG LEAD
SQL分析関数 PERCENT_RANK パーセンタイル
SQL分析関数 PERCENTILE_CONT PERCENTILE_DISC
SQL分析関数 CUME_DISTとCOUNT OVER SQLポケリ
WITH 再帰クエリ その2
SQLとJSON JSONデータをRDBに格納する
分析関数percentile_cont 中央値でノイズ除去
SQL分析関数 ROW_NUMBER RANK DENSE_RANK
SQL分析関数 FIRST_VALUE LAST_VALUE NTH_VALUE LAG LEAD
SQL分析関数 PERCENT_RANK パーセンタイル
SQL分析関数 PERCENTILE_CONT PERCENTILE_DISC
SQL分析関数 CUME_DISTとCOUNT OVER SQLポケリ
WITH 再帰クエリ その2
サイト内を検索
JSONでの末尾カンマ RDB保存時には注意 [SQLポケリ]
本日は、JSONネタである。
JSONで配列を記述することができる。
こんな感じである。
JavaScript ≒ Java ≒ C/C++
なので、C言語で配列を定義するのと同じ感じ。C言語では{}を使うけど。
JSONで良いところは、最後がカンマで終わっていても良いところ。配列要素が増えるということはよくあることなので、最後にカンマを書いておくと、変なSyntaxエラーに悩まされなくて済む。
C/C++でも余計にカンマ書いてもOK。
SQLでは最後にカンマがあるとSyntaxエラーになる。SELECT句でよくやってしまう間違い。
って書くと悲しいかなエラーになってしまう。
列が増えることを念頭に「カンマを先に書く」というお作法もある。例えばこんな感じ。
これなら、,fiveをコピって,sixを作れる。
でもなんか変。カンマは列名の後にきてないと違和感がある。最初のoneを改行するとさらに変になる。
oneだけ浮いてる。
JSONはカンマ書いてあっても大丈夫なので、きれいに書ける。
ほらね。
まぁ「カンマの位置なんてどうでもいいよ」という人にはどうでもいい話なのではあるが...
ただし、最後の余計なカンマは古いブラウザや正式なJSONではエラーになるので注意されたし。
RDBのJSON型に突っ込む場合もエラーになることもあるので注意。
正式なJSONと聞いて「はて?」と思われた方もいるかと。
「正式な」というよりかは、「厳密な」と言った方が良いかも。
最後の余計なカンマを付けると、厳密にいうと正式なJSONデータにはならないので、JSON.parseできない。データベースのJSON型にも保存することができない。
Postgresでやってみると...
ほら、怒られた。テーブルfooはJSON型の列をひとつだけ持っている。
エラーの原因はJSONのsyntaxエラーである。5の後のカンマね。それを取るとエラーにはならない。
厳密に正しいJSONデータになるので、保存できる。
あと、連想配列のフィールド名(キー)となる部分は、"で囲む必要がある。上記の例は配列なので、でてきていないが、連想配列を保存させたい場合は注意しないといけない。
nameはダメで、"name"としなければならない。同様に、ageも"age"にする。
ほらね。
サイト内を検索
JSONで配列を記述することができる。
こんな感じである。
var json_array = [1,2,3,4,5];
JavaScript ≒ Java ≒ C/C++
なので、C言語で配列を定義するのと同じ感じ。C言語では{}を使うけど。
int c_array[5] = {1,2,3,4,5};
JSONで良いところは、最後がカンマで終わっていても良いところ。配列要素が増えるということはよくあることなので、最後にカンマを書いておくと、変なSyntaxエラーに悩まされなくて済む。
var json_array = ['one', 'two', 'three', 'four', 'five', // ここにカンマを書いていてもOK ]; var json_array = ['one', 'two', 'three', 'four', 'five', 'six', // 上の'five'をコピってこの行を作れる。 ];
C/C++でも余計にカンマ書いてもOK。
int c_array[5] = {1,
2,
3,
4,
5,
};
SQLでは最後にカンマがあるとSyntaxエラーになる。SELECT句でよくやってしまう間違い。
select one, two, three, four, five, from number
って書くと悲しいかなエラーになってしまう。
列が増えることを念頭に「カンマを先に書く」というお作法もある。例えばこんな感じ。
select one ,two ,three ,four ,five from number
これなら、,fiveをコピって,sixを作れる。
select one ,two ,three ,four ,five ,six from number
でもなんか変。カンマは列名の後にきてないと違和感がある。最初のoneを改行するとさらに変になる。
select one ,two ,three ,four ,five from number
oneだけ浮いてる。
JSONはカンマ書いてあっても大丈夫なので、きれいに書ける。
var json_array = [ 'one', 'two', 'three', 'four', 'five', ];
ほらね。
まぁ「カンマの位置なんてどうでもいいよ」という人にはどうでもいい話なのではあるが...
ただし、最後の余計なカンマは古いブラウザや正式なJSONではエラーになるので注意されたし。
RDBのJSON型に突っ込む場合もエラーになることもあるので注意。
ここは後で追加しそう。というところだけケツカンマ付けておくっていうのが無難。
正式なJSON
正式なJSONと聞いて「はて?」と思われた方もいるかと。
「正式な」というよりかは、「厳密な」と言った方が良いかも。
最後の余計なカンマを付けると、厳密にいうと正式なJSONデータにはならないので、JSON.parseできない。データベースのJSON型にも保存することができない。
Postgresでやってみると...
postgres# insert into foo values('[1,2,3,4,5,]')
ERROR: invalid input syntax for type json
ERROR: invalid input syntax for type json
ほら、怒られた。テーブルfooはJSON型の列をひとつだけ持っている。
エラーの原因はJSONのsyntaxエラーである。5の後のカンマね。それを取るとエラーにはならない。
postgres# insert into foo values('[1,2,3,4,5]')
INSERT 0 1
INSERT 0 1
厳密に正しいJSONデータになるので、保存できる。
あと、連想配列のフィールド名(キー)となる部分は、"で囲む必要がある。上記の例は配列なので、でてきていないが、連想配列を保存させたい場合は注意しないといけない。
postgres# insert into foo values('{name:"asai",age:55}')
ERROR: invalid input syntax for type json
DETAIL: Token "name" is invalid.
ERROR: invalid input syntax for type json
DETAIL: Token "name" is invalid.
nameはダメで、"name"としなければならない。同様に、ageも"age"にする。
postgres# insert into foo values('{"name":"asai","age":55}')
INSERT 0 1
INSERT 0 1
ほらね。
関連記事
SQLとJSON JSONデータをRDBに格納する
分析関数percentile_cont 中央値でノイズ除去
SQL分析関数 ROW_NUMBER RANK DENSE_RANK
SQL分析関数 FIRST_VALUE LAST_VALUE NTH_VALUE LAG LEAD
SQL分析関数 PERCENT_RANK パーセンタイル
SQL分析関数 PERCENTILE_CONT PERCENTILE_DISC
SQL分析関数 CUME_DISTとCOUNT OVER SQLポケリ
WITH 再帰クエリ その2
SQLとJSON JSONデータをRDBに格納する
分析関数percentile_cont 中央値でノイズ除去
SQL分析関数 ROW_NUMBER RANK DENSE_RANK
SQL分析関数 FIRST_VALUE LAST_VALUE NTH_VALUE LAG LEAD
SQL分析関数 PERCENT_RANK パーセンタイル
SQL分析関数 PERCENTILE_CONT PERCENTILE_DISC
SQL分析関数 CUME_DISTとCOUNT OVER SQLポケリ
WITH 再帰クエリ その2
サイト内を検索
SQLとJSON JSONデータをRDBに格納する [SQLポケリ]
みなさんご存知のようにJavaScriptが大流行である。
サーバー側でもnodejsでJavaScriptだし。ブラウザでもなんかしようと思ったらJavaScriptだし。jQueryは便利だし。
key&valueのnoSQLならそのまま格納OKだし。RDBにだってJSON型があるし。なくても文字列型に入れることだって可能。
いっときはXMLが流行ったのだが、今はAWSのおかげかJSONをよく見るようになった。SQLポケリではXMLについては少しだけ載せているが、JSONについては「ほとんどない」。これは「いかん」時代に取り残されている感があるぞ、ということで、RDBにおけるJSONについて本ブログに書いて見るのである。
まずはJSON型のあるDBは?というと
1 Oracle
2 SQL Server
3 DB2
4 Postgres
5 MySQL
6 SQLite
なんとメジャーどころは全部JSON対応しているじゃない。
SQLiteについては型があってないようなものなので、厳密にはJSON型とはいえないかも知れないが、JSONデータを扱えるようになっている。
MS Accessについては微妙なところ。Access自身にJSON型は存在しないようだが、SQL Serverや他のDBを参照する場合にはJSON型をちゃんと認識するみたい。
ということで最近のRDBでは「JSONデータ型があるのが当たり前」という感じになっている。一時はnoSQLとか言われてたからねぇ。
JSONって何というところから説明し出すと「きりがない」と思われるので、はしょって説明する。「JSONとは」でググってみると...
JSONとは「JavaScript Object Notation」の略で、XMLなどと同様のテキストベースのデータフォーマットです。
とでてきた。
つまりは、JavaScriptでデータを定義する時に使う文法が「JSON」であるわけです。以下はよくみるJSONの例。
配列や連想配列を扱うことも可能である。以下は配列の例。
配列は[]で囲む。連想配列は{}で囲む。
配列の中に配列や連想配列を入れても良い。いわゆるネストが可能。以下は2次元配列の例。
配列の中が連想配列の場合は以下のようになる。
こんな感じのデータをRDBに格納することができるのがJSON型ということになる。
しかしパッと見た目、JSONといっても普通のテキストデータとなんら変わりがないように思える。
JSON型にすると何が違うのだろうか、varchar型に突っ込んでもOKな気がするが...
もちろん、JSONデータをvarchar型の列に記録してもOK。けれどもJSON型に記録しておけば便利なことが多くあるのである。そうじゃなければわざわざJSON型なんて作らないわけだし。
JSONデータはただのテキストデータと違って文法がある。ひとつのJSONデータは{}または[]で囲まれている必要がある。以下の文字列データはどれもJSONデータにはなり得ないものである。
このような正しくないデータをデータベース内に持ち込ませないようにすることができる。これはRDBのデータ型について一般的に言われていることでもある。難しく言うとデータ型という制約を列の属性として与えることで、データの整合性、信頼性が高まることになる。簡単に言えば「変なデータが紛れ込まなくなる」ということになる。
もうひとつの利点として、データベースの操作言語「SQL」でJSONデータを扱うことが可能になるといったことがある。JavaScriptだけを使っている状況であると、JSONデータから目的のデータを検索したりソートするにはJavaScriptで何かしらのコードを書いてやる必要がある。これって結構大変だったり、面倒だったりする。
まぁ、苦手かどうかは置いておくことにして、とにかくSQLを使って、JSON配列の中からデータを探す、と言うことが可能になるのです。ね便利でしょ?
本日はこの辺まで。
サイト内を検索
サーバー側でもnodejsでJavaScriptだし。ブラウザでもなんかしようと思ったらJavaScriptだし。jQueryは便利だし。
JavaScriptといえば、データの受け渡しはJSONだよね。
key&valueのnoSQLならそのまま格納OKだし。RDBにだってJSON型があるし。なくても文字列型に入れることだって可能。
いっときはXMLが流行ったのだが、今はAWSのおかげかJSONをよく見るようになった。SQLポケリではXMLについては少しだけ載せているが、JSONについては「ほとんどない」。これは「いかん」時代に取り残されている感があるぞ、ということで、RDBにおけるJSONについて本ブログに書いて見るのである。
まずはJSON型のあるDBは?というと
1 Oracle
2 SQL Server
3 DB2
4 Postgres
5 MySQL
6 SQLite
なんとメジャーどころは全部JSON対応しているじゃない。
SQLiteについては型があってないようなものなので、厳密にはJSON型とはいえないかも知れないが、JSONデータを扱えるようになっている。
MS Accessについては微妙なところ。Access自身にJSON型は存在しないようだが、SQL Serverや他のDBを参照する場合にはJSON型をちゃんと認識するみたい。
ということで最近のRDBでは「JSONデータ型があるのが当たり前」という感じになっている。一時はnoSQLとか言われてたからねぇ。
そもそもJSONとは?
JSONって何というところから説明し出すと「きりがない」と思われるので、はしょって説明する。「JSONとは」でググってみると...
JSONとは「JavaScript Object Notation」の略で、XMLなどと同様のテキストベースのデータフォーマットです。
とでてきた。
つまりは、JavaScriptでデータを定義する時に使う文法が「JSON」であるわけです。以下はよくみるJSONの例。
{key: 'asai',value: 53}
配列や連想配列を扱うことも可能である。以下は配列の例。
[1,2,3]
配列は[]で囲む。連想配列は{}で囲む。
配列の中に配列や連想配列を入れても良い。いわゆるネストが可能。以下は2次元配列の例。
[ [1,2,3,4,5,6,7,8,9], [2,4,6,8,10,12,14,16,18], [3,6,9,12,15,18,21,24,27], ]
配列の中が連想配列の場合は以下のようになる。
[
{key: 'asai',value: 53},
{key: 'atsushi',value: 20},
]
こんな感じのデータをRDBに格納することができるのがJSON型ということになる。
しかしパッと見た目、JSONといっても普通のテキストデータとなんら変わりがないように思える。
JSON型にすると何が違うのだろうか、varchar型に突っ込んでもOKな気がするが...
もちろん、JSONデータをvarchar型の列に記録してもOK。けれどもJSON型に記録しておけば便利なことが多くあるのである。そうじゃなければわざわざJSON型なんて作らないわけだし。
データの整合性
JSONデータはただのテキストデータと違って文法がある。ひとつのJSONデータは{}または[]で囲まれている必要がある。以下の文字列データはどれもJSONデータにはなり得ないものである。
朝井 淳
(1,2,3)
{name: 'asai'
このような正しくないデータをデータベース内に持ち込ませないようにすることができる。これはRDBのデータ型について一般的に言われていることでもある。難しく言うとデータ型という制約を列の属性として与えることで、データの整合性、信頼性が高まることになる。簡単に言えば「変なデータが紛れ込まなくなる」ということになる。
SQLでJSONを操作
もうひとつの利点として、データベースの操作言語「SQL」でJSONデータを扱うことが可能になるといったことがある。JavaScriptだけを使っている状況であると、JSONデータから目的のデータを検索したりソートするにはJavaScriptで何かしらのコードを書いてやる必要がある。これって結構大変だったり、面倒だったりする。
検索やソートなら「SQLなら楽勝」って言う方も多いのでは?そっちの方が大変?
まぁ、苦手かどうかは置いておくことにして、とにかくSQLを使って、JSON配列の中からデータを探す、と言うことが可能になるのです。ね便利でしょ?
本日はこの辺まで。
関連記事
JSONでの末尾カンマ RDB保存時には注意
分析関数percentile_cont 中央値でノイズ除去
SQL分析関数 ROW_NUMBER RANK DENSE_RANK
SQL分析関数 FIRST_VALUE LAST_VALUE NTH_VALUE LAG LEAD
SQL分析関数 PERCENT_RANK パーセンタイル
SQL分析関数 PERCENTILE_CONT PERCENTILE_DISC
SQL分析関数 CUME_DISTとCOUNT OVER SQLポケリ
WITH 再帰クエリ その2
JSONでの末尾カンマ RDB保存時には注意
分析関数percentile_cont 中央値でノイズ除去
SQL分析関数 ROW_NUMBER RANK DENSE_RANK
SQL分析関数 FIRST_VALUE LAST_VALUE NTH_VALUE LAG LEAD
SQL分析関数 PERCENT_RANK パーセンタイル
SQL分析関数 PERCENTILE_CONT PERCENTILE_DISC
SQL分析関数 CUME_DISTとCOUNT OVER SQLポケリ
WITH 再帰クエリ その2
サイト内を検索
分析関数percentile_cont 中央値でノイズ除去 [SQLポケリ]
というわけで前回からの続きである。
まずはデータを用意する。問題の部分を切り抜いてみた。
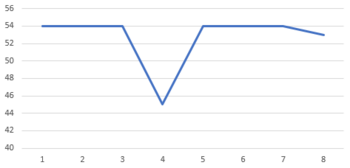
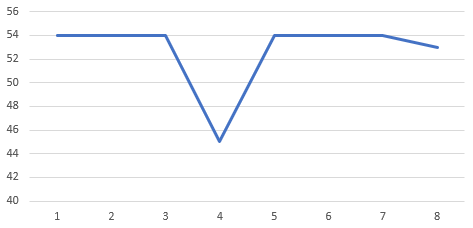
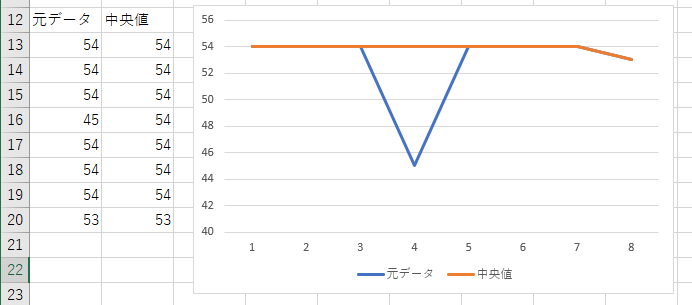
車速なので単位はkm/hと思われる。データの粒度は0.5秒単位。54km/hの定速で移動中な感じなのだが、途中にいきなり45km/hになっているところがある。0.5秒といった短い時間で9km/h減速して直後に戻っている。これってあきらかに「ノイズ」である。
Excelでグラフにしたらこんな感じ。
でもってこれをデータベースに取り込む。分析関数が使えないとダメなのでpostgresに取り込むことにした。
これで中央値は計算できた。しかしテーブル全体の中央値ではダメなので、overでウインドウを付けてみるものの、サポートしていないためか虚しくエラーになってしまった。
じゃあOracle12cでやってみるかと久しぶりにOracleを起動する。
Oracle12cでもpercentile_contとover(range between...はダメだった。avgなら行けるので移動平均なら計算できるのだが...やりたいのは中央値だしなぁ。
中央値を決定するためのspeedでのソートとウインドウを決定するためのnoでのソートの2種類のソート処理が発生するのでどうもできないみたいな感じ。ExcelのMEDIAN関数なら簡単にできるのではあるが、それだとSQLの解説にはならないし。
うーん、なんか良い逃げ道はないものか。
JSONデータに変換してみるか
なんかうまくいきそう。
JSONデータの
'[{"speed":54},{"sp...
となっている部分をどうやって作るかだが、ウインドウ関数でleadとlagを使うかな。文字列編集する感じでやってみるか。
ゲゲなんか大変な感じになってしまった。
先頭レコードなどでは、前後のデータがnullになってしまう可能性があるため、coalesceでnull値はカレント行のspeedの値で代用している。
JSONデータをテーブル値に変換してpercentile_contにかければできあがりなのだがSQLでどう書けば、サブクエリか?CROSS APPLY?関数の方がいい?
関数作ってしまった方がわかりやすいかも。
というわけでJSONデータを与えると中央値を戻す関数を作成する。
引数でもらったJSON型のデータをjson_to_recordsetでテーブル値に変換して、percentile_contで中央値を計算している。引数で渡ってくるJSONデータはlagとleadでカレント行からふたつ前と後の行からspeed列のデータを取得して文字列操作してJSONデータ化したものを想定している。
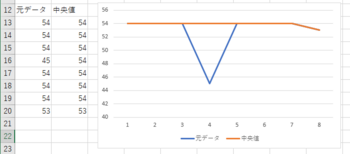
できちゃったかも。
見事に凹んだ感じの部分が平坦になっている。
サイト内を検索
まずはデータを用意する。問題の部分を切り抜いてみた。
54 54 54 45 54 54 54 53
車速なので単位はkm/hと思われる。データの粒度は0.5秒単位。54km/hの定速で移動中な感じなのだが、途中にいきなり45km/hになっているところがある。0.5秒といった短い時間で9km/h減速して直後に戻っている。これってあきらかに「ノイズ」である。
Excelでグラフにしたらこんな感じ。
でもってこれをデータベースに取り込む。分析関数が使えないとダメなのでpostgresに取り込むことにした。
create table sensor_data ( no serial, speed integer ); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(45); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(53);
postgres=# select * from sensor_data; no | speed ----+------- 1 | 54 2 | 54 3 | 54 4 | 45 5 | 54 6 | 54 7 | 54 8 | 53 (8 行)
select percentile_cont(0.5) within group (order by speed) from sensor_data;
これで中央値は計算できた。しかしテーブル全体の中央値ではダメなので、overでウインドウを付けてみるものの、サポートしていないためか虚しくエラーになってしまった。
じゃあOracle12cでやってみるかと久しぶりにOracleを起動する。
Oracle12cでもpercentile_contとover(range between...はダメだった。avgなら行けるので移動平均なら計算できるのだが...やりたいのは中央値だしなぁ。
中央値を決定するためのspeedでのソートとウインドウを決定するためのnoでのソートの2種類のソート処理が発生するのでどうもできないみたいな感じ。ExcelのMEDIAN関数なら簡単にできるのではあるが、それだとSQLの解説にはならないし。
うーん、なんか良い逃げ道はないものか。
JSONデータに変換してみるか
select percentile_cont(0.5) within group (order by speed)
from json_to_recordset('[{"speed":54},{"speed":54},{"speed":54},{"speed":45},{"speed":54}]'::json)
as x(speed integer);
なんかうまくいきそう。
JSONデータの
'[{"speed":54},{"sp...
となっている部分をどうやって作るかだが、ウインドウ関数でleadとlagを使うかな。文字列編集する感じでやってみるか。
select no, speed,
'['
|| '{"speed":' || coalesce(lag(speed,2) over (order by no),speed) || '}'
|| ',' || '{"speed":' || coalesce(lag(speed,1) over (order by no),speed) || '}'
|| ',' || '{"speed":' || speed || '}'
|| ',' || '{"speed":' || coalesce(lead(speed,1) over (order by no),speed) || '}'
|| ',' || '{"speed":' || coalesce(lead(speed,2) over (order by no),speed) || '}'
||
']'
window_speed_data
from sensor_data
ゲゲなんか大変な感じになってしまった。
先頭レコードなどでは、前後のデータがnullになってしまう可能性があるため、coalesceでnull値はカレント行のspeedの値で代用している。
JSONデータをテーブル値に変換してpercentile_contにかければできあがりなのだがSQLでどう書けば、サブクエリか?CROSS APPLY?関数の方がいい?
関数作ってしまった方がわかりやすいかも。
というわけでJSONデータを与えると中央値を戻す関数を作成する。
create function get_median(json) returns integer as $$
declare
var_median integer;
begin
select
percentile_cont(0.5) within group (order by speed)
into var_median
from json_to_recordset($1) as x(speed integer);
return var_median;
end;
$$ language 'plpgsql';
引数でもらったJSON型のデータをjson_to_recordsetでテーブル値に変換して、percentile_contで中央値を計算している。引数で渡ってくるJSONデータはlagとleadでカレント行からふたつ前と後の行からspeed列のデータを取得して文字列操作してJSONデータ化したものを想定している。
select q.no, q.speed, get_median(q.window_speed_data::json)
from (
select no, speed,
'['
|| '{"speed":' || coalesce(lag(speed,2) over (order by no),speed) || '}'
|| ',' || '{"speed":' || coalesce(lag(speed,1) over (order by no),speed) || '}'
|| ',' || '{"speed":' || speed || '}'
|| ',' || '{"speed":' || coalesce(lead(speed,1) over (order by no),speed) || '}'
|| ',' || '{"speed":' || coalesce(lead(speed,2) over (order by no),speed) || '}'
||
']'
window_speed_data
from sensor_data
) q;
no | speed | get_median ----+-------+------------ 1 | 54 | 54 2 | 54 | 54 3 | 54 | 54 4 | 45 | 54 5 | 54 | 54 6 | 54 | 54 7 | 54 | 54 8 | 53 | 53 (8 行)
できちゃったかも。
見事に凹んだ感じの部分が平坦になっている。
関連記事
分析関数percentile_cont 中央値でノイズ除去
SQL分析関数 ROW_NUMBER RANK DENSE_RANK
SQL分析関数 FIRST_VALUE LAST_VALUE NTH_VALUE LAG LEAD
SQL分析関数 PERCENT_RANK パーセンタイル
SQL分析関数 PERCENTILE_CONT PERCENTILE_DISC
SQL分析関数 CUME_DISTとCOUNT OVER SQLポケリ
WITH 再帰クエリ その2

分析関数percentile_cont 中央値でノイズ除去
SQL分析関数 ROW_NUMBER RANK DENSE_RANK
SQL分析関数 FIRST_VALUE LAST_VALUE NTH_VALUE LAG LEAD
SQL分析関数 PERCENT_RANK パーセンタイル
SQL分析関数 PERCENTILE_CONT PERCENTILE_DISC
SQL分析関数 CUME_DISTとCOUNT OVER SQLポケリ
WITH 再帰クエリ その2
SQLポケリには、分析関数も載ってますよ。よかったらどうぞ。
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2017/02/18
- メディア: 単行本(ソフトカバー)
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2019/05/16
- メディア: 単行本(ソフトカバー)
サイト内を検索
Copyright Atsushi Asai Google+朝井淳
AREarthroid さん

-
nice! 100
記事 507
テーマ パソコン・インターネット (10位)
プロフィール
ブログを紹介する
![[改訂第4版]SQLポケットリファレンス](https://images-fe.ssl-images-amazon.com/images/I/51T1BV7VWXL._SL160_.jpg "[改訂第4版]SQLポケットリファレンス")
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2017/02/18
- メディア: 単行本(ソフトカバー)
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2019/05/16
- メディア: 単行本(ソフトカバー)
![[データベースの気持ちがわかる]SQLはじめの一歩 (WEB+DB PRESS plus)](https://images-fe.ssl-images-amazon.com/images/I/51YR52dRIQL._SL160_.jpg "[データベースの気持ちがわかる]SQLはじめの一歩 (WEB+DB PRESS plus)")
[データベースの気持ちがわかる]SQLはじめの一歩 (WEB+DB PRESS plus)
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2015/03/03
- メディア: 単行本(ソフトカバー)

Access クエリ 徹底活用ガイド ~仕事の現場で即使える
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2018/05/25
- メディア: 大型本


